Linux
Linux
- 1: Network
- 2: 内核
- 3: 操作系统
- 3.1: Alpine
- 3.2: Flatcar Container Linux
- 4: 虚拟化
- 4.1: Namespace
- 5: Systemd
- 6: 服务器配置 SSH 公钥登陆
- 7: 调度算法
- 8: Overlay2
- 9: OCI
- 10: tcpdump 抓包
- 11: 容器网络和iptables
1 - Network
Network
Network
SDN(Software Defined Networking)是当前热门技术之一,目前已经普遍得到大家共识。本文整理了SDN实践中的一些基本理论和实践案例心得。
1.1 - 基础知识
网络基础概念
网络基础知识
vxlan
全称 Virtual extensible local area network,是用三层协议封装的二层协议,允许第二层数据包在第三层网络上传输。通过 Overlay 技术旨在扩展 vlan, 以解决大型云计算部署中虚拟网络数量不足的问题。
DSR(Direct Server Return)
默认情况下,cilium 的 BPF NodePort 实现以 SNAT 模式运行。也就是说,当节点外部流量到达且节点确定 NodePort 或者 xternallPs 服务的后端位于远程节点时,则 该节点通过执行 SNAT 代表其将请求重定向到远程后端。不需要额外的 MTU 更改,而代价是来自后端的答复。
cilium 下通过将 nodeport.mode 改成 dsr 更改此设置,使 Cilium 的 bpf nodeport实现在 dsr 模式下运行。
DSR 需要在 Native-Routing,不能再任何 tunneling 模式下工作。
XDP
express data path ,能够在网络包进入用户态直接对网络包进行过滤或者处理。XDP 依赖于 ebpf技术。
Encapsulation(封装)
使用基于 UDP 的封装协议 vxlan 形成一个 tunnel。
优点简单,缺点是由于添加了 header,MTU过大低于本地路由。导致特定网络连接的最大吞吐率低,可以通过巨型帧缓解。
1.2 - 网络协议
网络协议
tcp: 流量控制 超时重传 拥塞控制
传输层的数据包大小超过 MSS (TCP最大报文段长度),就要将数据分块,这样即使中途有一个分块出问题,只需要重传这个分块,而不用重新发送整个数据包。 在 TCP 协议中,每个分块称为 TCP段。
网络层最常用的是IP协议,将传输层的报文作为数据部分,再加上IP包头组装成IP报文,如果报文大小超过 MTU(以太网中一般为1500字节)就会再次进行分片,得到一个即将发送到网络的IP报文。
IP地址分成的两种意义:
- 一是网络号,负责标识该IP地址是属于哪个【子网】;
- 二是主机号,负责标识同一【子网】下的不同主机;
需要配合子网掩码才能计算出 IP地址的网络号和主机号。 如: 10.100.122.0/24 /24就是 255.255.255.0 子网掩码,二进制有24个1.
- 计算网络号: 将IP与子网掩码做 AND 运算
- 计算主机号: 将子网掩码取反后与IP地址进行与运算
网络接口层: 生成了 IP 头部之后,接下来要交给 网络接口层 在 IP 头部的前面加上 MAC 头部,并封装成数据帧发送到网络上。
可靠传输 TCP
TCP报文头部格式:
- 源端口号 :确认应用
- 目的端口号 :确认目的应用
- 序号 :解决包乱序问题
- 确认序号 :确认发出去对方是否收到,没收到就重新发送,解决丢包问题
- 状态位 :SYN(发起一个连接) ACK(回复) RST(重新连接) FIN(结束连接),带有状态位的包的发送,引起双方状态变更。
- 首部长度 :
- 保留
- 校验
- 窗口大小 : TCP要控制流量,通信双方个声明一个窗口(缓存大小),表示当前处理的能力。还要拥塞控制,控制发送的速度。
- 紧急指针
- 选项
网络包 IP
IP 报文头部:
- 版本
- 首部长度
- 服务类型
- 协议 : http通过tcp传输,填写 06,表示协议为tcp
- 校验
- ttl
- 源 IP 地址 :客户端输出的IP地址
- 目标 IP 地址 : web 服务器 IP
MAC
MAC 头部:
- 接收方 MAC 地址
- 发送方 MAC 地址
- 协议类型 :IP协议和 ARP协议
HTTP1.0 无状态、无连接
HTTP1.1 持久连接 请求管道化 增加缓存处理(新的字段如cache-control) 增加Host字段、支持断点传输等
HTTP2.0 二进制分帧 多路复用(或连接共享) 头部压缩 服务器推送
HTTPS 优化:
tls协议,目的是为了通过非对称加密握手协商或者交换出对称加密密钥。
尽量序言用 ECDHE 密钥交换算法替代 RSA 算法,使用 tls1.3 (简化了握手的步骤,握手只要1RTT)
证书优化
会话复用
SYN seq = clinet_isn
ACK = seq + 1 SEQ = server_isn
ACK = server_isn + 1
三次握手建立连接的主要原因是防止历史连接 初始化了连接。
1.3 - 网关协议
网关协议
网关协议
kubernetes 需要安装 CNI 网络插件进行请求通信。遇到的问题如:
- arp 地址不正确,服务请求返回异常
- 开启 bgp 协议
- 网卡的几种模式
- …
路由器工作在 IP 层,其作用是根据 IP 地址将数据包传输到正确的目的地,因此路由器必须知道网络的“地图”才能正确投递,这个”地图“就是存储在路由表中的路由规则,简称路由。
根据获得路由的方式可以分为:
- 静态路由:管理员配置的路由
- 动态路由:路由器通过算法动态学习和调整得到的路由。常说的路由协议就是指 动态路由的学习算法。
根据作用域不同可以分为:
- 内部网关协议(IGP),通常包括 RIP 和 OSPF
- 边界网关协议(BGP)
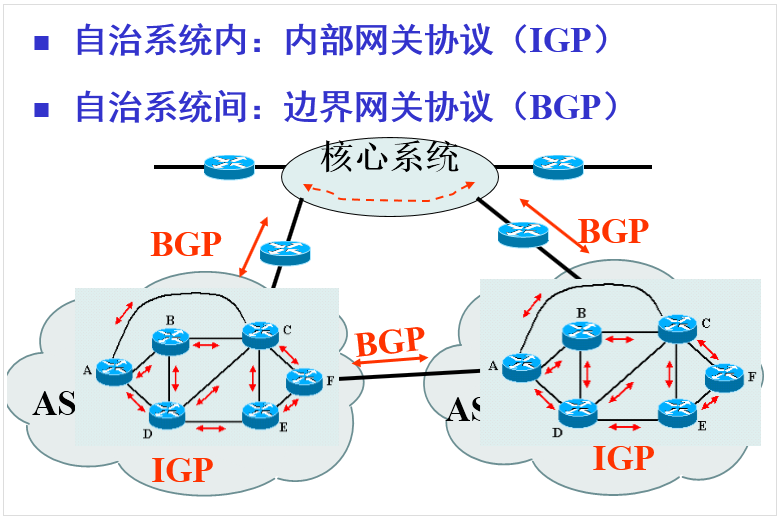
BGP路由(边界网关协议)
Border Gateway Protocol
当网络过大时,会导致路由表过大而难以维护,这时候采用分治的方法,将一个大网络划分为若干个小网络,这些小网络称为自治系统(AS),BGP就是用于自治系统间的通信。
边界网关协议就像是互联网的邮政服务,当有人把信投进邮筒时,邮政服务会处理邮件,并选择一条高效的路线将信投递给收件人。 同样地,当有人通过互联网提交数据时,BGP负责寻找数据能传播的可用路径,并选择最佳路由,通常在自治系统之间跳跃。
并不是 是不是所有的 AS 之间的通信都需要 BGP ,当只有两 AS 间存在多条路径,需要做路由策略和选择才需要 BGP,如果AS只有一出口或者所有的出口指向一个 ISP 时,是不需要 BGP 的。
基本概念
BGP 允许基于策略的路由选择,策略与多种因素相关,有 AS 的网络管理者确定,人为影响的因素较大。
每个划分后的小网络称为 AS ,每个 AS 都有自己的 AS号码(ASN)。根据类型不同,也被分为不同类型的 AS 。
BGP 是运行在 TCP 协议之上的,BGP 的邻居关系(或称为对等实体 peer)是通过人工配置实现的,对等实体之间通过 TCP 端口 179 创建会话交换数据。 BGP 路由器会周期发送19自己的保持存活(keep-alive)消息维持连接。在各种路由协议中,只有 bgp 使用 TCP 作为传输层协议。
与其他路由协议对比:
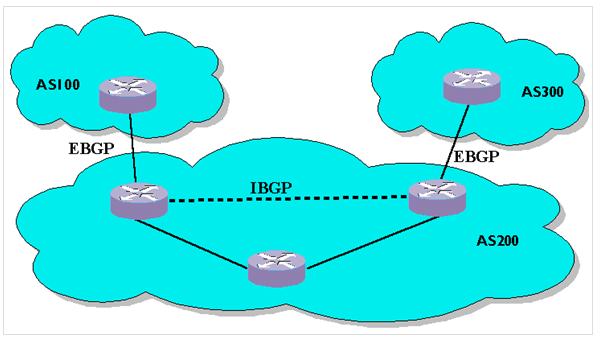
BGP 有两种邻居,其中在同一个 AS 内的 BGP 邻居称为 IBGP(Interior BGP),不同 AS 间的邻居称为 EBGP(Exterior BGP),无论是 IBGP 或者 EBGP,上面都运行着 BGP 协议,也就是说与 BGP 路由器直连的内部路由器不一定是它的 IBGP。
注意: BGP 邻居不是自己发现的,而是手动配置的,原因是:
- 可以与对端设备用任何IP地址建立邻居,而不必限于某个固定的接口IP。这样当两台设备采用环回地址而非直连地址建立 BGP 邻居时,即时主链路断了,也可以切回到备份链路上,保持邻居不断。
- 可以跨越多台设备建立邻居。当一个 AS 有多个设备运行 BGP 建立域内全连接时,不必每台设备物理直连,只要用IGP保证建立邻居的地址可达,即可建立全网连接,减少不必要的链路。
路由注入及宣告
BGP路由器的路由注入和通告都是为了修改 BGP 路由表。
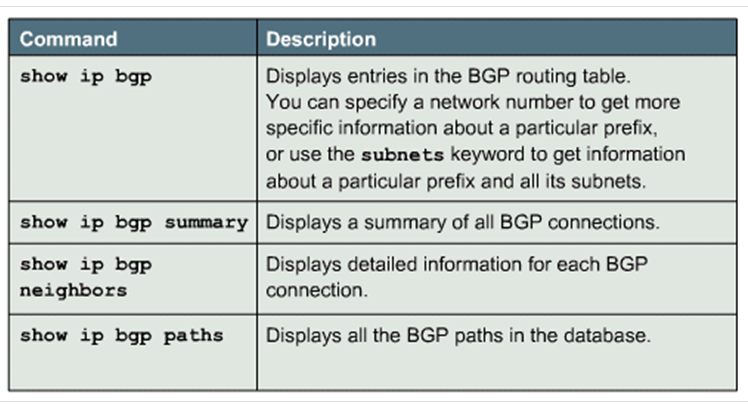
当路由器之间建立 BGP 邻居之后,可以相互交换 BGP 路由。一台运行了 BGP 协议的路由器,会将 BGP 得到的路由与普通的路由分开存放,所以 BGP 路由器会同时拥有两张路由表。 普通路由的称为 IGP路由表,用 show ip route 就能看到的路由表。IGP路由表的路由信息只能从 IGP 协议和手工配置获得,并且只能传递给 IGP 协议; 另一张是 BGP路由表,用命令 show ip bgp 查看。
初始状态下,BGP的路由表为空,没有任何路由,要让 BGP 传递相应的路由,只能先将该路由注入BGP路由表,之后才能在BGP邻居之间传递。注入的方式:
- 动态注入
- 半动态路由注入
- 静态路由注入
在注入路由后, BGP 路由器之间会进行通告。通告要遵守以下规则:
- BGP 路由器只把自己使用的路由通告给相邻体
- BGP 路由器从 EBGP 获得的路由会向所有BGP相邻体通告
- 从 IBGP 获得的路由不会向 IBGP 相邻体通告
- 从 IBGP 获得的路由是否通告给 EBGP 相邻体要依 IGP 和 BGP 同步的情况而定。
检查 BGP 的命令:
IGP (内部网关协议)
在 AS 内部的协议,主要包括 RIP协议 和 OSPF协议。
RIP
距离向量协议,UDP协议,端口号为 520。
工作过程:
- RIP 路由器中初始的路由表只有自己的直连路由;路由表中每一项为一个三元组,即目标网络,该条路由信息的下一条地址以及距离;距离定义为经过的路由器数。
- 每个路由器发起自己的更新周期,将自己的路由表信息发送给相邻的路由表,接受到该路由表信息的临接路由表更新自己的路由表信息;
- 存在路由环路问题
OSPF(Open Shortest Path First)
使用的是链路状态路由算法,直接使用IP协议,协议类型为89.
1.4 - 操作网络命令
操作网络命令
Linux 下控制网络的命令:
- curl & wget
- ping
- tracepath & traceroute
- mtr
- host
- whois
- ifplugstatus 是否有网线插入网络设备接口, sudo apt-get install ifplugd
- ifconfig
- ifdown & ifup 启用或者禁用设备
- dhclient
- netstat
route 命令
route 命令用于显示和操作 IP路由表。
要实现两个不同的子网之间的通信,需要一台连接两个网络的路由器,或者同时位于两个网络的网关来实现。
在Linux系统中,设置路由通常是为了解决以下问题: Linux机器在局域网中,局域网有一个网关,能够让机器访问 Internet ,那么需要将这台机器的IP地址设置为Linux机器的默认路由。 直接执行route命令来添加路由,不会永久保存。当网卡重启或者机器重启之后,该路由会失效;可以在 /etc/rc.local 中添加 route 命令来保证该路由设置永久有效。
命令参数:
-c 显示更多信息
-n 不解析名字
-v 显示详细的处理信息
-F 显示发送信息
-C 显示路由缓存
-f 清除所有网关入口的路由表
-p 与 add 命令一起使用时使路由具有永久性
add:添加一条路由
del:删除一条路由
-net:目标地址是一个网络
-host:目标地址是一个主机
netmask:当添加一个网络路由时,需要使用网络掩码
gw:路由数据包通过网关。注意,指定的网关必须能够达到。
metric:设置路由跳数
Command 指定想运行的命令 (Add/Change/Delete/Print)
Destination 该路由的网络目标
mask Netmask 指定与网络目标的网络掩码(子网掩码)
Gateway 指定网络目标定义的地址集和子网掩码可以到达的前进或者下一跳跃点 IP 地址
metric Metric为路由指定一个整数成本值,当在路由表的多个路由中进行选择时可以使用
实例1
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.25.64.1 0.0.0.0 UG 0 0 0 eth0
172.25.64.0 0.0.0.0 255.255.240.0 U 0 0 0 eth0
第二行表示主机所在网络的地址为 172.25.64.0,若数据传送目标是在本局域网内通信,则可以直接通过 eth0 转发数据包; 第一行表示传送的目标是访问 Internet,则由接口 eth0 将数据包发送到网关 172.25.64.1。
其中 Flags 标志说明:
- U Up表示此路由当前为启动状态
- H Host表示此网关为一个主机
- G Gateway 表示网关是一个路由器
- R Reinstate Route,使用动态路由重新初始化的路由
- D Dynamically 此路由是动态性地写入
- M Modified 此路由是由路由守护程序或者导向器动态修改
- ! 表示此路由当前为关闭状态
路由工作原理
路由:数据从源主机到目标主机的转发过程(路径)。
路由器和交换机的区别:
- 数据在同一网段的转发用交换机。
- 数据在不同网段的转发用路由器。
路由器:能够将数据包转移到正确目的地,并在转交过程中选择最佳路径的设备。
原理
根据路由表查找接口进行数据转发,相邻的路由器接收到数据包并且查看数据包的目标地址,再转发到网络接口和对应的主机。
路由表的形成
路由表是路由器中维护的路由条目的集合,路由器根据路由表做路径选择。 路由表中有直连网段和非直连网段两种。
直连网段:路由器上配置了接口的 IP 地址,并且状态是 Up 状态,由此产生直连路由。 非直连网段:没有跟路由器直接连接的网段,就是非直连网段。
对于非直连网段,需要静态路由和动态路由,将网段添加到路由表中。
静态路由和默认路由
- 静态路由:由管理员手工配置,优点在于稳定且可以对路由的行为进行控制,是单向的,缺乏灵活性。
- 默认路由:当路由器在路由表中找不到目标网络的路由条目时,路由器把请求转发到默认路由接口。
当路由表中存在静态路由和默认路由的时候,静态路由优先级最高,匹配上了会立刻转发;如果没有匹配上静态路由,则按照默认路由进行转发。
命令行查看路由表
route -n
netstat -rn
ip route show dev <interface>
设置网络接口
ifconfig
netmask
#eg
ifconfig eth0 192.168.1.100 netmask 255.255.255.0
ifconfig 命令已经被新的 ip 命令所替代,建议在新的系统中使用 ip 命令来管理网络接口。
#新增一个IP地址
ip addr add 192.168.1.100/24 dev eth0
#查询
ip addr show eth0
#删除
ip addr del 192.168.1.100/24 dev eth0
1.5 - docker 四种网络模型
- bridge: 使用 –network bridge 指定,默认使用 docker0 ;
- host: 使用 –network host 指定;
- none: 使用 –network none 指定;
- container:使用 –network container:(name/id)指定。
Docker 四种网络模型:
1. bridge 模式
Docker的默认网络设置,此模式会为每一个容器分配 Network Namespace,设置ip等,并将一个主机上的 Docker 容器连接到一个虚拟网桥上(docker0)上。
2. host 模式
启动容器时使用host模式,就不会获取一个独立的network Namespace,而是和宿主机公用一个 Network Namespace。 容器将不会虚拟出自己的网络,配置IP等,都是使用宿主机的IP和端口。
3. none 模式
在 none 模式下,Docker容器拥有自己的 Network Namespace,但是,并不为docker容器进行任何网络配置。 也就是说这个docker容器没有网卡、IP、路由等信息。
4. container
这个模式是新创建的容器和已存在的容器共享一个 Network Namespace,而不是和宿主机共享。 新创建的容器不会创建自己相关的网卡,而是和指定的容器共享Ip,端口范围等。 同样,除了网络方面。在文件系统,进程列表等方面还是资源隔离的。
常用命令
docker network -h
docker network create my-bridge -d bridge --subnet=172.21.0.0/16
docker run -d --net my-bridge --name nginx nginx
1.6 - dns
DNS(Domain Name System,域名系统)是因特网的一项服务,它用于将域名转换为IP地址,而域名又由各级域名服务器进行解析。
常见的DNS记录类型:
1. A记录(Address Record)
A记录用于将域名指向一个IPv4地址。每个域名可以有多个A记录,以支持负载均衡和冗余。
2. CNAME记录(Canonical Name Record)
将一个域名别名映射到另一个域名。允许多个域名指向同一个IP地址或者主机名,通常用于子域名的重定向。
3. MX记录(Mail Exchange Record)
MX记录用于指定邮件服务器的域名。MX记录包含邮件服务器的优先级。
4. NS记录(Name Server Record)
指定负责解析该域名的域名服务器。NS记录通常在域名注册商处设置。
5. CAA记录(Certification Authority Authorization Record)
CAA记录用于限制CA颁发证书的域名。指定哪些证书颁发机构(CAs)被授权为该域名颁发 SSL/TLS 证书。通过CAA记录可以防止中间人攻击和其他安全漏洞。
6. TXT记录(Text Record)
TXT记录用于存储文本信息。TXT记录可以包含任意的ASCII或UTF-8编码的文本。可以用于多用用途,如域验证、SPF记录(反垃圾邮件)、DMARC记录(邮件认证、报告和一致性)、DKIM记录(安全)等。
7. PTR记录(Pointer Record)
PTR记录用于将IP地址转换为域名。PTR记录通常由DNS服务器自动生成。
8. SOA记录(Start of Authority Record)
包含DNS区域的管理信息,如区域的原始名称服务器、区域管理员的电子邮件地址、区域的过期时间等。
9. AAAA记录(IPv6 Address Record)
用于将域名指向一个IPv6地址。每个域名可以有多个AAAA记录,以支持IPv6地址。
10. SRV记录(Service Record)
SRV记录用于指定特定服务的服务器。SRV记录包含服务的名称、协议、端口号、优先级和权重。
11. SPF记录(Sender Policy Framework Record)
SPF记录用于指定哪些邮件服务器可以发送邮件。SPF记录通常由域名注册商设置。
2 - 内核
内核算是一个程序员的基本功,更好的理解底层技术。在处理问题时,可以挖掘到问题本质,而不只是停留在技术表面。 特别是在容器领域设计到 cgroups / namespace / unionfs 等基础技术,需要更加深入学习、掌握。
内核是操作系统的核心,其主要功能有:
- 响应中断,执行中断服务程序
- 管理多个进程,调度和分享处理器时间
- 管理进程地址空间和内存管理
- 网络和进程间通信等系统服务程序
内核的活动范围:
- 运行于用户空间,习性用户进程
- 运行于内核空间,处理进程上下文,代表某个特定进程的执行
- 运行于内核空间,处理中断上下文,与进程无关,处理某个特定的中断
本系列围绕在 “进程管理”,“内存管理”,“IO栈”,“网络栈”四大脉络,总结 Linux Kernel 的一些常识知识。
Kernel 版本
Linux内核根据版本具有不同的支持级别,长期支持版本(LTS),超长期支持(SLTS)。

# 查询内核版本
$ uname -a
Linux xxx 5.10.16.3-microsoft-standard-WSL2 #1 SMP Fri Apr 2 22:23:49 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
$ uname -a
Linux xxx 5.4.0-105-generic #119-Ubuntu SMP Mon Mar 7 18:49:24 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
$ uname -a
Linux xxx 5.15.81-flatcar #1 SMP Tue Dec 6 22:42:27 -00 2022 x86_64 Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz GenuineIntel GNU/Linux
# 查询系统版本
$ cat /etc/issue
Ubuntu 20.04.4 LTS \n \l
内核版本说明:
- 前三组数字为:主版本号 + 次版本号 + 修订版本号。
- SMP : 对称多处理机,表示内核支持多核、多处理器。
- x86_64 : 采用64位的cpu
抽象级别和层次
最底层是硬件系统,包括cpu和ram,此外硬盘和网络接口也是硬件系统的一部分。
硬件系统之上是内核,是操作系统的核心。内核是运行在内存中的软件,向cpu发送指令。内核管理硬件系统,是硬件系统和应用程序之间进行通信的接口。
进程是计算机中运行的程序,由内核统一管理,组成了最顶层,称为 用户空间。

内核和用户进程之间最主要的区别是:内核在内核模式下运行,而用户进程是在用户模式中运行。在内核模式中运行的代码可以不受限的访问cpu和内存,这种模式功能强大,因为内核进程可以让整个系统崩溃。只有内核可以访问的空间称为内核空间。
2.1 - 修改内核参数
查看、修改 Linux 内核参数
查看、修改 Linux 内核参数
查看
方法一:
通过 /proc/sys 目录,使用 cat 命令查看对应文件的内容。
此目录是 Linux 内核启动后生成的伪目录,其目录下的 net 文件夹中存放了当前系统中生效的所有内核参数、目录树结构与参数的完整名称相关。
如 net.ipv4.tcp_tw_recycle ,对应的文件就是 /proc/sys/net/ipv4/tcp_tw_recycle,文件的内容就是参数值。
执行如下命令查看:
cat /proc/sys/net/ipv4/tcp_tw_recycle
方法二:
通过 /etc/sysctl.conf 文件进行查看,执行以下命令,查看当前系统中生效的所有参数。
sysctl -a
修改
- 方法一:通过修改 /proc/sys 目录中对应的文件,临时修改,重启后会重置为原参数值,一般用于临时性验证。
- 方法二:通过修改 /etc/sysctl.conf 文件进行修改,该方法修改的参数值,永久生效。
- 修改执行的参数值: sysctl -w kernel.domainname=“example.com”
- 修改配置文件: vim /etc/sysctl.conf
- 配置生效: sysctl -p
2.2 - 内存管理
内存管理
内核所管理的另一个重要资源是内存。为了提高效率,由硬件管理虚拟内存,内存是按照所谓的 内存页 方式进行管理的。 Linux 包括了管理可用内存的方式,以及物理和虚拟映射所使用的硬件机制。不过内存管理要管理的不止 4KB 缓冲区。
内核不仅管理服务器上的可用物理内存,还可以创建和管理虚拟内存。 内核通过硬盘上的存储空间来实现虚拟内存,这块区域称为 交换空间(swap space)。内核不断在交换空间和实际的物理内存之间反复交换虚拟内存中的内容。
Linux提供了对 4KB 缓冲区的抽象,如slab分配器。这种内存管理模式使用 4KB 缓冲器为基数,然后从中分配结构,并跟踪内存页使用情况, 比如哪些内存页是满的,哪些页面没有完全使用,哪些页面为空。
2.3 - 虚拟内存
虚拟内存
虚拟内存
做单片机的时候,程序需要烧录进芯片,这样程序才能跑起来。单片机的CPU是直接操作内存的【物理地址】。
这种情况下,在内存中想同时运行两个程序是不可能的,第二个程序在相同的位置会擦掉第一个程序的所有内容,程序会崩溃。
操作系统时如何解决这个问题的?
这里关键的问题是两个程序都引用了绝对的物理地址,这个正是我们需要避免的。
我们把进程所使用的的地址隔离起来,让操作系统为每个进程分配独立的一套【虚拟地址】,至于虚拟地址最终怎么样落到物理内存里,对进程来说是透明的。
操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。
如果程序要访问虚拟地址的时候,由操作系统进行转换成不同的物理地址,这样不同的进程运行写入不同的物理地址,就不会冲突。
- 我们程序所使用的内存地址叫做虚拟内存地址。
- 实际存在硬件里面的空间地址叫做物理内存地址。
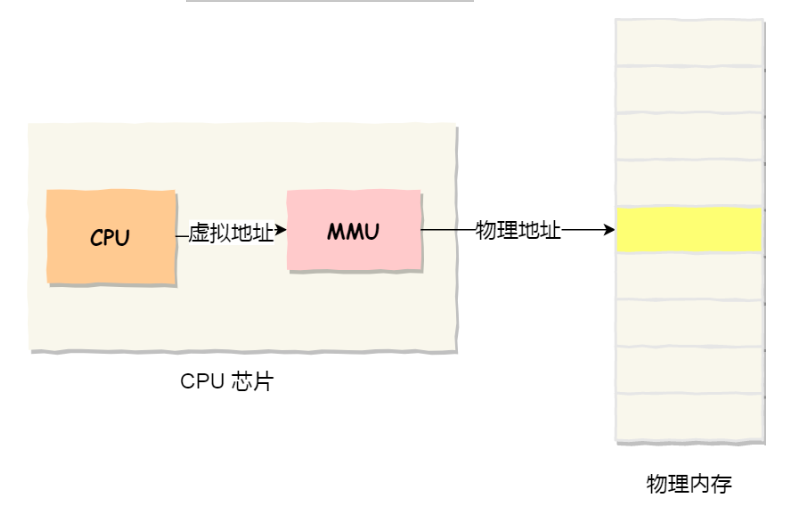
进程持有的虚拟地址会通过 CPU 芯片中的内存管理单元(MMU)的映射关系,来转换成物理地址,然后通过物理地址访问内存。
内核通过硬盘上的存储空间来实现虚拟内存,这块区域称为 交换空间(swap space)。内核不断在交换空间和时间的物理内存之间反复交换虚拟内存中的内容。
操作系统是如何管理虚拟地址和物理地址之间的关系?
主要有两种方式,分别的内存分段和内存分页。
内存分段
程序是由若干个逻辑分段组成的,可由代码分段、数据分段、栈段、堆段组成。 不同的段有不同的属性,所以就用分段(Segmentation)的形式把这些段分离出来。
分段的办法解决了程序不需要关心物理内存地址的问题,但是也有一些缺点:
- 内存碎片问题
- 内存交换的效率低的问题
内存分页
分段的好处是能产生连续的内存空间,但是会出现 外部内存碎片 和 内存交换的空间太大 的问题。 要解决这些问题,就要想出能少出现内存碎片的办法。另外,当需要进行内存交换的时候,让需要交换写入或者从磁盘装载的数据少一点,这样就可以解决,也就是内存分页(Paging)。
分页是把整个虚拟和物理内存空间切成一段固定尺寸的大小,这样一个连续并且固定的内存空间,我们叫做 页。在 Linux 下,每页大小为 4KB 。
虚拟地址和物理地址之间通过 页表 来映射。
页表存储在内存里,内存管理单元(MMU)就将虚拟内存地址转换成物理地址的工作。
当进程访问的虚拟地址在页表中查不到时,系统会产生一个 缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
分页是怎么样解决分段的【外部内存碎片和内存效率低】的问题?
内存分页由于内存空间都是预先划分好的,也就不会像内存分段一样产生间隙非常小的内存。采用分页,页和页之间是紧密排列的,所以不会有外部碎片。
但是,因为内存分页之间分配的最下单位是一页,所以会出现内存浪费,所以针对 内存分页机制会有 内部内存碎片 的现象。
如果内存空间不够,操作系统会把其他正在运行的进程中[最近没有被用]的内存页释放掉,也就是暂时写在硬盘上,称为 换出(Swap Out)。一旦需要的时候,再加载进来,称为 换入**(Swap In)**。所以一次性写入磁盘的只有少数页,不会花太多时间,内存交换的效率就相对比较高。
分页会产生的页表过大问题,有了多级页表,解决空间上问题,但是这会导致CPU在寻址的过程中,需要有很多层表参加,加大了时间的开销。 根据程序的局部性原理,在CPU芯片中加入了 TLB,负责缓存最近常被访问的页表项,大大提高了地址的转换速度。
3 - 操作系统
操作系统
操作系统
3.1 - Alpine
Alpine
Alpine 操作系统是一个面向安全的轻型Linux发行版。相比其他操作系统,体积非常小。提供自己的包管理工具 apk,可以直接安装各种软件。
Alpine Docker 镜像也继承了 Alpine Linux 发行版的优势,体积只有5M左右。作为基础镜像,有许多好处,如下载快,镜像安全性高,占用更少磁盘等。
apk 包管理
首先替换默认的安装源,采用国内一些源:
- 中科大:http://mirrors.ustc.edu.cn/alpine/
- 阿里云:https://mirrors.aliyun.com/alpine/
- 清华大学:https://mirror.tuna.tsinghua.edu.cn/alpine/
使用方法:
sed -i 's/dl-cdn.alpinelinux.org/mirror.tuna.tsinghua.edu.cn/g' /etc/apk/repositories
apk update # 更新索引生效
apk upgrade --no-cache # 安装可用的升级
Alpine中软件安装包名字可能回合其他发行版不同,可以在 alpine-package 网站搜索。
包管理命令:
查找包:
apk search # 查找所有可用包
apk search -v # 带描述
安装包:
apk add openssh # 安装
apk add openssh vim # 安装多个
apk add --no-cache vim # 不使用本地镜像源缓存,相当于先执行 update ,再执行add
安装信息:
apk info # 已安装的包
apk info -a vim # 显示完整的软件包信息
更新包:
apk upgrade # 升级所有软件
apk upgrade openssh # 指定升级
apk upgrade openssh vim # 指定升级多个
删除包:
apk del vim # 删除
服务管理
alpine 没有使用 systemctl 进行服务管理,使用 rc 系列命令。
精简版的 alpine 没有rc系列命令,可以使用 apk add –no-cache openrc 安装
- rc-update 增加或者删除服务
- rc-status 状态管理
- rc-service 管理服务的状态
- openrc 管理不同的运行级
rc-status -a # 列出所有服务
rc-udate add docker boot # 增加服务到系统启动时运行
rc-service networking restart # 重启网络服务
docker-alpine 镜像
大部分官方镜像都支持使用 Alpine 作为基础镜像。
制作镜像
FROM alpine:3
RUN sed -i 's/dl-cdn.alpinelinux.org/mirror.tuna.tsinghua.edu.cn/g' /etc/apk/repositories
RUN apk update \
&& apk upgrade --no-cache \
&& apk add --no-cache vim
相关资源
- Alpine 官网:https://www.alpinelinux.org/
- Alpine 官方仓库:https://github.com/alpinelinux
- Alpine 官方镜像:https://hub.docker.com/_/alpine/
- Alpine 官方镜像仓库:https://github.com/gliderlabs/docker-alpine
3.2 - Flatcar Container Linux
Flatcar Container Linux
Flatcar 是一种容器优化的操作系统,提供了一个最小的操作系统镜像,其中仅包含运行容器所需要的工具。操作系统通过不可变的文件系统交付,并包括自动院子更新。
安装
支持大多数的云供应商、虚拟化平台和裸机服务器上运行。这里主要介绍几种不同的方式在裸机安装:
- 从 ISO 镜像安装
- 使用 PXE 引导
- 使用 iPXE 启动
- 使用 flatcar-install 安装
iPXE
iPXE 是一个开源网络启动固件。提供了一个完整的 PXE 实施,增强了其他功能,例如:
- 通过 HTTP 从 web 服务器启动
- 从无线网络启动
- 从广域网启动
- 从 Infiniband 网络启动
- 使用脚本控制启动过程
- …
iPXE 同时支持 UEFI 和 BIOS 平台。
PXE
PXE 是 Perboot eXecution Environment 的缩写,意为“预启动执行环境”,这种机制可以使计算机通过网络来引导。现在的绝大多数电脑都可以设置通过 PXE 启动。 PXE 的工作原理是 PXE Client 通过 DHCP 获取 IP,并由 DHCP 服务器告诉客户端启动文件的位置,再通过 TFTP 协议传输引导文件,最终引导电脑启动。
使用 flatcar-install 安装
使用 flatcar-install 脚本安装.
fatcar-install -d /dev/sda -i ignition.json
ignition.json 文件包括从 Butane Config 生成的用户信息,否则无法登陆 Flatcar 实例。 如果是在 VMware 上安装,传递 -o vmware_raw 以安装特定于 VMware 的镜像。
flatcar-install -d /dev/sda -i ignition.json -o vmware_raw
选择 channel
Flatcar Container Linux根据每个频道的不同时间表自动更新,可以禁用此功能。生产环境使用 stable channel,要确保使用稳定版本,使用以下选项:
flatca-install -d /dev/sda -C stable
Butane Configs
默认情况下,没有密码和其他方式登陆到新的 Flatcar Container Linux 系统,配置账户、添加 systemd 单元等最简单的方法是通过 Butane Configs。 使用 Butane 生成 Ignition 配置后,安装脚本将处理 ignition.json 文件。
为用户指定ssh密钥core的yaml文件如下:
variant: flatcar
version: 1.0.0
passwd:
users:
- name: core
ssh_authorized_keys:
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDGdByTgSVHq.......
将其转译为 json 文件:
cat c1.yaml |docker run --rm -i quay.io/coreos/butane:latest > ignition.json
sudo ifconfig eno1 172.xxx.xxx.xxx netmask 255.255.255.0
sudo route add default gw 172.xxx.xxx.1
#... 添加 config.json 文件
sudo -E flatcar-install -C stable -d /dev/sda -i config.json
passwd:
users:
- name: "core"
ssh_authorized_keys:
- "ssh-rsa AAAA
- name: "aaa"
password_hash: "$6$brlNJCk"
ssh_authorized_keys:
- "ssh-rsa AAAAB3NzaC1yc2E"
groups:
- "sudo"
- "docker"
networkd:
units:
- name: 00-eno.network
contents: |
[Match]
Name=eno*
[Network]
Bond=bond0
- name: 10-bond0.netdev
contents: |
[NetDev]
Name=bond0
Kind=bond
[Bond]
Mode=active-backup
MIIMonitorSec=1
- name: 20-bond0.network
contents: |
[Match]
Name=bond0
[Network]
DNS=172.xxx
DNS=172.xxx
Address=172.xxx/24
Gateway=172.16.164.1
systemd:
units:
- name: containerd.service
dropins:
- name: 10-use-cgroupfs.conf
contents: |
[Service]
Environment=CONTAINERD_CONFIG=/usr/share/containerd/config-cgroupfs.toml
- name: settimezone.service
enabled: true
contents: |
[Unit]
Description=Set the time zone
[Service]
ExecStart=/usr/bin/timedatectl set-timezone America/Los_Angeles
RemainAfterExit=yes
Type=oneshot
[Install]
WantedBy=multi-user.target
- name: systemd-networkd.service
enable: true
- name: update-engine.service
mask: true
- name: locksmithd.service
mask: true
storage:
filesystems:
- name: "OEM"
mount:
device: "/dev/disk/by-label/OEM"
format: "btrfs"
files:
- filesystem: "OEM"
path: "/grub.cfg"
mode: 0644
append: true
contents:
inline: |
set linux_append="$linux_append systemd.unified_cgroup_hierarchy=0 systemd.legacy_systemd_cgroup_controller"
- path: /etc/flatcar-cgroupv1
mode: 0444
- filesystem: "root"
path: "/etc/hostname"
mode: 0644
contents:
inline: nodeIp
- path: /etc/systemd/timesyncd.conf
filesystem: root
mode: 0644
contents:
inline: |
[Time]
NTP=xxx
4 - 虚拟化
虚拟化
虚拟化
4.1 - Namespace
Namespace
目前的容器技术、虚拟化技术都能做到资源层面的隔离和限制。
对于容器技术而言,实现资源层面上的限制和隔离,依赖于 Linux 内核所提供的 cgroup 和 namespace 技术。
- cgroup的主要作用:管理资源的分配、限制。
- namespace的主要作用:封装抽象,限制,隔离,使命名空间内的进程看起来拥有全局资源。
Namespace 是什么?
Namespace 是 Linux 内核的一项特性,可以对内核资源进行分区,使一组进程可以看到一组资源;而另一组进程可以看到另一组不同的资源。 该功能的原理时一组资源和进程使用相同的 namespace ,但是这些 namespace 实际上引用的是不同的资源。
Linux 默认提供了多种 namespace,用于对多种不同资源进行隔离。
在之前,单独使用 namespace 的场景比较有限,但是 namespace 却是容器化技术的基石。
发展历程
Namespace 开始进入 Linux Kernel 的版本是 2.4.x,才开始实现每个进程的 namespace。 Linux 3.8 中完全实现了 User Namespace 的相关功能集成到内核。这样 Docker 以及其他容器技术所使用的到的 namespace 相关功能就基本实现了。
Namespace 类型
- Cgroup - CLONE_NEWCGROUP 控制 Cgroup root directory cgroup 根目录。
- IPC - CLONE_NEWIPC 控制 System V IPC POSIX message qucucs 信号量,消息队列
- Nework - CLONE_NEWNET 控制 Network devics , stacks ,ports ,etc 网络设备,协议栈,端口等
- Mount - CLONE_NEWNS 控制 Mount points 挂载点
- PID - CLONE_NEWPID 控制 Process IDs 进程号
- Time - CLONE_NEWTIME 控制时钟
- User - CLONE_NEWUSER 用户和组ID
- UTS - CLONE_NEWUTS 系统主机名和NIS主机名(也称域名)
1. Cgroup namespaces
Cgroup namespace 是进程的 cgroups 的虚拟化视图,通过 /proc/[pid]/cgroup 和 /proc/[pid]/mountinfo 展示。
az6c@WXMIS037:/proc/6184$ ps -ef|grep nginx
root 6184 6163 0 10:20 ? 00:00:00 nginx: master process nginx -g daemon off;
...
az6c@WXMIS037:/proc/6184$ cat cgroup
13:rdma:/
12:pids:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
11:hugetlb:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
10:net_prio:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
9:perf_event:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
8:net_cls:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
7:freezer:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
6:devices:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
5:memory:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
4:blkio:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
3:cpuacct:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
2:cpu:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
1:cpuset:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
0::/
az6c@WXMIS037:/proc/6184$ cat mountinfo
157 114 0:50 / / rw,relatime master:3 - overlay overlay rw,lowerdir=/var/lib/docker/overlay2/l/VVZTUGALNCARSF7HMUB445JPUY:/var/lib/docker/overlay2/l/G3PPKI2BXA3PKTPL7VURBQVVKD:/var/lib/docker/overlay2/l/7NVHGK2ITPX2UT2YGDAJFJE2QD:/var/lib/docker/overlay2/l/GZGJV5VQ4T2ZGCCMGFKXOESBQP:/var/lib/docker/overlay2/l/PRL3DYKGN4DW6BAEZZ3B2YMPMZ:/var/lib/docker/overlay2/l/JT7YW37MP5DRFGKGMD3STR64HG:/var/lib/docker/overlay2/l/VVD7Z66THINOLXHB3V3UHUT5K7,upperdir=/var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a/diff,workdir=/var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a/work
158 157 0:53 / /proc rw,nosuid,nodev,noexec,relatime - proc proc rw
159 157 0:54 / /dev rw,nosuid - tmpfs tmpfs rw,size=65536k,mode=755
160 159 0:55 / /dev/pts rw,nosuid,noexec,relatime - devpts devpts rw,gid=5,mode=620,ptmxmode=666
161 157 0:56 / /sys ro,nosuid,nodev,noexec,relatime - sysfs sysfs ro
162 161 0:57 / /sys/fs/cgroup rw,nosuid,nodev,noexec,relatime - tmpfs tmpfs rw,mode=755
163 162 0:33 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/cpuset ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,cpuset
164 162 0:34 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/cpu ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,cpu
165 162 0:35 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/cpuacct ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,cpuacct
166 162 0:36 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/blkio ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,blkio
167 162 0:37 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/memory ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,memory
168 162 0:38 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/devices ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,devices
169 162 0:39 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/freezer ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,freezer
170 162 0:40 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/net_cls ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,net_cls
171 162 0:41 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/perf_event ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,perf_event
172 162 0:42 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/net_prio ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,net_prio
173 162 0:43 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/hugetlb ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,hugetlb
174 162 0:44 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/pids ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,pids
175 162 0:45 / /sys/fs/cgroup/rdma ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,rdma
176 159 0:52 / /dev/mqueue rw,nosuid,nodev,noexec,relatime - mqueue mqueue rw
177 159 0:58 / /dev/shm rw,nosuid,nodev,noexec,relatime - tmpfs shm rw,size=65536k
178 157 8:16 /var/lib/docker/containers/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd/resolv.conf /etc/resolv.conf rw,relatime - ext4 /dev/sdb rw,discard,errors=remount-ro,data=ordered
179 157 8:16 /var/lib/docker/containers/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd/hostname /etc/hostname rw,relatime - ext4 /dev/sdb rw,discard,errors=remount-ro,data=ordered
180 157 8:16 /var/lib/docker/containers/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd/hosts /etc/hosts rw,relatime - ext4 /dev/sdb rw,discard,errors=remount-ro,data=ordered
121 158 0:53 /bus /proc/bus ro,nosuid,nodev,noexec,relatime - proc proc rw
122 158 0:53 /fs /proc/fs ro,nosuid,nodev,noexec,relatime - proc proc rw
123 158 0:53 /irq /proc/irq ro,nosuid,nodev,noexec,relatime - proc proc rw
124 158 0:53 /sys /proc/sys ro,nosuid,nodev,noexec,relatime - proc proc rw
125 158 0:59 / /proc/acpi ro,relatime - tmpfs tmpfs ro
126 158 0:54 /null /proc/kcore rw,nosuid - tmpfs tmpfs rw,size=65536k,mode=755
127 158 0:54 /null /proc/keys rw,nosuid - tmpfs tmpfs rw,size=65536k,mode=755
128 158 0:54 /null /proc/timer_list rw,nosuid - tmpfs tmpfs rw,size=65536k,mode=755
129 158 0:54 /null /proc/sched_debug rw,nosuid - tmpfs tmpfs rw,size=65536k,mode=755
130 161 0:60 / /sys/firmware ro,relatime - tmpfs tmpfs ro
cgroup namespce 提供一系列的隔离支持:
- 防止信息泄漏(容器不应该看到容器外的任何信息)
- 简化容器迁移
- 限制容器进程资源,因为会把 cgroup 文件系统进行挂载,使得容器进程无法获取上层的访问权限。
Namespace 的主要 API
clone(2)
系统调用 clone(2) 创建一个新的进程,根据参数中的 CLONE_NEW* 设置,逐个对实现对应的配置功能。当然这个系统调用也实现了一些与 namespace 无关的功能。
unshare(2)
系统调用 unshare(2)将进程分配至新的 namespace ,同样,也会根据参数中的 CLONE_NEW* 设置调整实现对应的配置功能。
setns(2)
将进程移动到某一存在的 namespace,这会导致 /proc/[pid]/ns 对应的目录中内容的变更。 进程创建的子进程可以通过调用 unshare(2) 和 setns(2) 来调整所属的 namespace。
5 - Systemd
Systemd 是一系列工具的集合,其作用也远远不仅四启动操作系统,还接管了后台服务、结束、状态查询,以及日志归档、设备管理、段元管理、定时任务等许多职责,并支持通过特定事件和特定端口数据触发的任务。
Systemd 是一系列工具的集合,包括了一个专用的系统日志管理服务:Journald。这个服务的初衷是克服 syslog 服务的日志内容容易伪造和日志格式不统一等缺点。 Journald 使用二进制格式报错所有的日志信息,因此日志信息很难被伪造。提供 journalctl 命令来查看日志信息。
Unit 文件
Systemd 可以管理所有的系统资源,不同的资源统称为 Unit(单位)。
Unit文件统一了过去不同系统资源配置格式,例如服务的启/停、定时任务、设备自动挂载、网络配置、虚拟内存配置等。而 Systemd 通过不同的文件后缀区分这些配置文件。
支持的12种 Unit 文件类型
.timer:配置在特定时间触发的任务,替代了 Crontab的功能
.service:封装守护进程的启动、停止、重启和重载操作,是最常见的一种 Unit 文件
.target:用于对 Unit 文件进行逻辑分组,引导其他 Unit 的执行
.automount:用于控制自动挂载文件系统,相当于autofs 服务。
.device: 对于/dev目录下的设备,主要用于定义设备之间的依赖关系
.mount:定义系统结构层次中的一个挂载点,替代过去的 /etc/fstab 配置文件
.scope: Systemd运行时产生的文件,描述一些系统服务的分组信息
.slice:用于表示一个 cGroup 的树,通常用户不会自己创建
.snapshot
.socket
.swap
目录
按照约定,放置在指定的是哪个系统目录之一中。优先级高的目录里的文件会被使用。
- /etc/systemd/system :系统或者用户自定义的配置文件(优先级最高)
- /run/systemd/system :软件运行时生成的配置文件
- /usr/lib/systemd/system :系统或者第三方软件安装时添加的配置文件
文件结构
例如:
[Unit]
Description=Hello World
After=docker.service
Requires=docker.service
[Service]
TimeoutStartSec=0
ExecStartPre=-/usr/bin/docker kill busybox1
ExecStartPre=-/usr/bin/docker rm busybox1
ExecStartPre=/usr/bin/docker pull busybox
ExecStart=/usr/bin/docker run --name busybox1 busybox /bin/ sh -c "while true; do echo Hello World; sleep 1; done"
ExecStop="/usr/bin/docker stop busybox1"
ExecStopPost="/usr/bin/docker rm busybox1"
[Install]
WantedBy=multi-user.target
Unit 文件可以分为三个配置区段:
- Unit 段:所有 Unit 文件通用,配置服务的描述、依赖和随系统启动的方式。
- Service 段:后缀为 .service 特有的,用于定义服务的具体管理和操作方法。
- Install 段: 和 Unit 段 作用相同。
Unit 段
- Description
- Documentation
- Requires
- Wants
- After
- Before
- Binds To
- Part Of
- OnFailure
- Conflicts
Install 段
这部分配置的目标通常是特定运行目标的 .target 文件,用来使得服务在系统启动时自动运行。这个区段可以包含三种启动约束:
- WantedBy
- RequiredBy
- Also 当前 Unit enable/disabled时,同时 enable/disable 其他 Unit
- Alias 启动的别名
systemctl list-units –type=target # 获取当前正在使用的运行目标
Service 段
声明周期相关:
- type :启动时的进程行为
- simple: 默认值,执行 execstart 指定的命令,启动主进程
- forking 从父进程创建子进程,创建后父进程会立即突出
- oneshot 一次性进程, systemd 会等当前服务退出,再继续往下执行
- dbus
- notify 当前服务启完毕,通知 systemd,再继续往下执行
- idle 若有其他任务执行完毕,当前服务才会运行
- RemainAfterExit
- ExecStart
- ExecStartPre
- ExecStartPos
- ExecReload
- ExecStop
- ExecStopPost
- RestartSec
- Restart 重新启动, always on-success on-failure on-abnormal on-abort on-watchdog
- TimeoutStartSec 启动服务时等待的秒数,一般docker容器拉镜像时间较长设置0,关闭超时检测
- TimeoutStopSec 停止服务时的等待秒数,如果超过这个时间仍然没有停止,syystemd会使用 sigkill 信号强行杀死服务的进程。
服务上下文配置相关
- Environment 为服务指定环境变量
- EnvironmentFile
- Nice 服务进程的优先级,越小越高,默认为0,范围是 -20~19
- WorkingDirectory
- RootDirectory 服务进程的根目录
- User
- Group
:如果在 ExecStart、ExecStop 等属性中使用了 Linux 命令,则必须要写出完整的绝对路径。对于 ExecStartPre 和 ExecStartPost 辅助命令,若前面有个 “-” 符号,表示忽略这些命令的出错。
Systemd 资源管理
Systemctl 命令:
# 列出正在运行的 Unit
systemctl list-units
# 列出所有Unit,包括没有找到配置文件的或者启动失败的
systemctl list-units --all
# 列出所有没有运行的 Unit
systemctl list-units --all --state=inactive
# 列出所有加载失败的 Unit
systemctl list-units --failed
# 列出所有正在运行的、类型为 service 的 Unit
systemctl list-units --type=service
# 查看 Unit 配置文件的内容
systemctl cat docker.service
查看 Unit 的状态:
# 显示系统状态
systemctl status
# 显示单个 Unit 的状态
systemctl status bluetooth.service
# 立即启动一个服务
sudo systemctl start apache.service
# 立即停止一个服务
sudo systemctl stop apache.service
# 重启一个服务
sudo systemctl restart apache.service
# 杀死一个服务的所有子进程
sudo systemctl kill apache.service
# 重新加载一个服务的配置文件
sudo systemctl reload apache.service
# 重载所有修改过的配置文件
sudo systemctl daemon-reload
# 显示某个 Unit 的所有底层参数
systemctl show httpd.service
# 显示某个 Unit 的指定属性的值
systemctl show -p CPUShares httpd.service
# 设置某个 Unit 的指定属性
sudo systemctl set-property httpd.service CPUShares=500
查看 Unit 的依赖关系:
# 列出所有依赖,默认不会列出 target 类型
systemctl list-dependencies nginx.service
# 列出所有依赖,包括 target 类型
systemctl list-dependencies --all nginx.service
Systemd 工具集
- systemctl:用于检查和控制各种系统服务和资源的状态
- bootctl:用于查看和管理系统启动分区
- hostnamectl:用于查看和修改系统的主机名和主机信息
- journalctl:用于查看系统日志和各类应用服务日志
- localectl:用于查看和管理系统的地区信息
- loginctl:用于管理系统已登录用户和 Session 的信息
- machinectl:用于操作 Systemd 容器
- timedatectl:用于查看和管理系统的时间和时区信息
- systemd-analyze 显示此次系统启动时运行每个服务所消耗的时间,可以用于分析系统启动过程中的性能瓶颈
- systemd-ask-password:辅助性工具,用星号屏蔽用户的任意输入,然后返回实际输入的内容
- systemd-cat:用于将其他命令的输出重定向到系统日志
- systemd-cgls:递归地显示指定 CGroup 的继承链
- systemd-cgtop:显示系统当前最耗资源的 CGroup 单元
- systemd-escape:辅助性工具,用于去除指定字符串中不能作为 Unit 文件名的字符
- systemd-hwdb:Systemd 的内部工具,用于更新硬件数据库
- systemd-delta:对比当前系统配置与默认系统配置的差异
- systemd-detect-virt:显示主机的虚拟化类型
- systemd-inhibit:用于强制延迟或禁止系统的关闭、睡眠和待机事件
- systemd-machine-id-setup:Systemd 的内部工具,用于给 Systemd 容器生成 ID
- systemd-notify:Systemd 的内部工具,用于通知服务的状态变化
- systemd-nspawn:用于创建 Systemd 容器
- systemd-path:Systemd 的内部工具,用于显示系统上下文中的各种路径配置
- systemd-run:用于将任意指定的命令包装成一个临时的后台服务运行
- systemd-stdio- bridge:Systemd 的内部 工具,用于将程序的标准输入输出重定向到系统总线
- systemd-tmpfiles:Systemd 的内部工具,用于创建和管理临时文件目录
- systemd-tty-ask-password-agent:用于响应后台服务进程发出的输入密码请求
6 - 服务器配置 SSH 公钥登陆
服务器配置 SSH 公钥登陆
服务器配置 SSH 公钥登陆
- Xshell 工具可以生成公私钥对,输入密码加密。
- 在服务器端编辑 /etc/ssh/sshd_conf 。
RSAAuthentication yes #开启RSA认证 PubkeyAuthentication yes #开启公钥认证 AuthorizedKeysFile .ssh/authorized_keys #设置公钥的保存位置,默认为用户目录下的.ssh目录,没有可自行创建。 - 将保存好的 .pub 公钥文件 上传到服务器,保存在 ~/.ssh/authorized_keys 文件中。
- 设置权限
chmod 700 .ssh chmod 600 ~/.ssh/authorized_keys - 重启 sshd 服务以使配置生效
service sshd restart - 在测试公钥登陆成功后可以再次编辑 /etc/ssh/sshd_config 文件,关闭密码登陆,提高安全性。
PasswordAuthentication no
7 - 调度算法
操作系统的三大调度机制,分别是 进程调度、页面置换、磁盘调度算法。
操作系统的三大调度机制,分别是 进程调度、页面置换、磁盘调度算法。
进程调度算法
进程调度算法也称为 CPU 调度算法,毕竟进程是由 CPU 调度的。
当 CPU 空闲时,操作系统就会选择内存中的某个 [就绪状态] 的进程,并给其分配 CPU。
什么时候发生 CPU 调度?
- 当进程从运行状态转到等待状态 - 非抢占式调度
- 当进程从运行状态转到就绪状态 - 抢占式调度
- 当进程从等待状态转到就绪状态 - 抢占式调度
- 当进程从运行状态转到终止状态 - 非抢占式调度
非抢占式的意思是,当进程正在运行时,就会一直运行,知道该进程完成或者发生某个事件而被阻塞时,才会把 CPU 让给其他进程。 抢占式的意思是,进程正在运行时,可以被打断,使其把 CPU 让给其他进程。那抢占的原则一般有三种,分别是时间片原则、优先权原则、短作业优先原则。
常见的调度算法:
- 先来先服务调度算法
- 最短作业优先调度算法
- 高响应比优先调度算法
- 时间片轮转调度算法
- 最高优先级调度算法
- 多级反馈队列调度算法
内存页置换算法
内存页置换算法的功能是,当出现缺页异常,需要调入新页面而内存已满时,选择被置换的物理页。 也就是说选择一个物理页换出到磁盘,然后把需要访问的页面换入到物理页。
算法的目标是,尽可能少的换入和换出的次数,常见的算法有:
- 最佳页置换算法
- 先进先出置换算法
- 最近最久未使用的置换算法
- 时钟页置换算法
- 最不常用置换算法
磁盘调度算法
8 - Overlay2
Overlay2
Docker 的存储驱动 Overlay2,可以通过 storage-driver 参数进行指定,也可以在 /etc/docker/daemon.json 文件中通过 storage-driver 字段进行设置。
存储驱动的作用
Docker 将容器镜像做了分层存储,每个层相当于包含着一条 Dockerfile 的指令。而这些层在磁盘上存储方式,已经在启动容器时,如何组织这些层,并提供可写层,便是存储驱动的主要作用。
不同的存储驱动实现不同,性能也有差异,同时使用不同的存储驱动会导致占用的磁盘空间有所不同。
驱动
- overlay2
- fuse-overlayfs
- btrfs
- zfs
- aufs
- overlay
- devicemapper
- vfs
OverlayFS
overlay2 是 overlay 的升级版,这两个存储驱动所用的都是 OverlayFS。它的出现是为了解决 overlay 存储驱动 inode 耗尽问问题。
启动一个容器后,查看 mount 挂载
$ mount |grep overlay
overlay on /var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a/merged type overlay
(rw,relatime,
lowerdir=/var/lib/docker/overlay2/l/VVZTUGALNCARSF7HMUB445JPUY:/var/lib/docker/overlay2/l/G3PPKI2BXA3PKTPL7VURBQVVKD:/var/lib/docker/overlay2/l/7NVHGK2ITPX2UT2YGDAJFJE2QD:/var/lib/docker/overlay2/l/GZGJV5VQ4T2ZGCCMGFKXOESBQP:/var/lib/docker/overlay2/l/PRL3DYKGN4DW6BAEZZ3B2YMPMZ:/var/lib/docker/overlay2/l/JT7YW37MP5DRFGKGMD3STR64HG:/var/lib/docker/overlay2/l/VVD7Z66THINOLXHB3V3UHUT5K7,
upperdir=/var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a/diff,
workdir=/var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a/work)
- 查看 merged 目录,为容器根目录,可以通过写文件测试。
- lowerdir 是 mount 中指定的目录。
- upperdir
- workdir
查看上级目录
$ ls /var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a
diff link lower merged work
- lower 是基础层,可以包含多个 lowerdir
- diff 是可写层,即挂载时的 upperdir,在容器内变更的文件都在这层存储
- merged 是最终合并的结果,即容器给我们呈现的结果
Overlay2
经过上面对 Docker 启动容器之后挂载的 OverlayFS 的介绍后, Overlay2 的工作流程应该会比较清楚。
将镜像各层为 lower 基础层,同时增加 diff 这个可写层,通过 OverlayFS 的工作机制,最终将 merged 作为容器内的文件目录展示给用户。
其中对 lower 的深度有硬编码的限制,当前限制为 128 。如果在使用的过程中遇到错误,有可能表示超过了最大深度限制,必须减少层数。
9 - OCI
OCI
为了推进容器化技术的工业标准化,在2015年在 DockerCon 上一些公司共同宣布成立开放容器项目(OCP),后更名为 OCI。
OCI(Open Container Initiative)
主要的目标是建立容器格式和运行时的工业开放通用标准。
OCI指定的标准有三个:
- runtime-spec
- image-spec
- distribution-spec
10 - tcpdump 抓包
tcpdump 抓包
Tcpdump 是一个网络数据包截获分析工具。支持针对网络层、协议、主机、网络或者端口的过滤。并提供and or not 等逻辑语句。
tcpdump tcp -i eth1 -t -s 0 -c 100 and dst port ! 22 and src net 192.168.1.0/24 -w ./tag.cap
解释如下:
- tcp :过滤数据包的类型,放到第一个参数位置, icmp arp tcp udp 等
- -i eth1 :只抓经过接口 eth1 的包
- -t :不显示时间戳
- -s 0 :抓完整的数据包,因为抓取数据包时默认的长度为68字节
- -c 100 :只抓取 100 个数据包
- dst port ! 22 : 不抓取目标端口是22的数据包
- src net 192.168.1.0/24 : 数据包的源网络地址是 192.168.1.0
- -w ./tag.cap 保存成 cap 文件,方便 wireshark 分析
11 - 容器网络和iptables
容器网络和iptables
容器网络和iptables
启动一个容器,查看iptables
$ iptables-save
# Generated by iptables-save v1.8.4 on Thu Jan 12 10:28:13 2023
*security
:INPUT ACCEPT [3207420:579585381]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [3205687:578296425]
COMMIT
# Completed on Thu Jan 12 10:28:13 2023
# Generated by iptables-save v1.8.4 on Thu Jan 12 10:28:13 2023
*raw
:PREROUTING ACCEPT [3281739:594537318]
:OUTPUT ACCEPT [3205687:578296425]
COMMIT
# Completed on Thu Jan 12 10:28:13 2023
# Generated by iptables-save v1.8.4 on Thu Jan 12 10:28:13 2023
*nat
:PREROUTING ACCEPT [5948:1205704]
:INPUT ACCEPT [120:27480]
:OUTPUT ACCEPT [21:1239]
:POSTROUTING ACCEPT [21:1239]
:DOCKER - [0:0]
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
COMMIT
# Completed on Thu Jan 12 10:28:13 2023
# Generated by iptables-save v1.8.4 on Thu Jan 12 10:28:13 2023
*mangle
:PREROUTING ACCEPT [3281739:594537318]
:INPUT ACCEPT [3207420:579585381]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [3205687:578296425]
:POSTROUTING ACCEPT [3205687:578296425]
COMMIT
# Completed on Thu Jan 12 10:28:13 2023
# Generated by iptables-save v1.8.4 on Thu Jan 12 10:28:13 2023
*filter
:INPUT ACCEPT [187:49960]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [68:7214]
:DOCKER - [0:0]
:DOCKER-ISOLATION-STAGE-1 - [0:0]
:DOCKER-ISOLATION-STAGE-2 - [0:0]
:DOCKER-USER - [0:0]
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
COMMIT
# Completed on Thu Jan 12 10:28:13 2023
iptables 基础
一个 iptables 上可能包含多个表,表可能包含多个链。链可以是内置的或者用户定义的。 链可能包含多个规则,规则是为数据包定义的。
表是一堆链,链是一堆防火墙规则。
iptables -> tables -> Chains -> Rules
Iptables 表和链
四个内置表
1. 过滤表
默认表,表内有内置链。
- INPUT链 - 传入防火墙
- OUTPUT链 - 从防火墙传出
- FORWARD链 - 本地服务器上另一个NIC的数据包。对于通过本地服务器路由的数据包。
2. NAT表
NAT表具有以下内置链
- PREROUTING 链 - 在路由之前更改数据包。 用于 DNAT (目标NAT)
- POSTROUTING 链 - 在路由后更改数据包。用于SNAT(源 NAT)
- OUTPUT 链 - 防火墙上本地生成的数据包的NAT。
3. Mangle表
用于专门的数据包更改,改变TCP报文头中的QOS位,具有以下内置链:
Docker 网络与 iptables
dockerd daemon 参数有 –iptables 参数,默认为 true ,默认添加 iptables 规则。如果启动时添加 –iptables=false 参数,默认没有任何规则。
利用 docker in docker 启动一个镜像 docker:dind 的容器,进入之后查看 iptable 规则。
# Generated by iptables-save v1.8.6 on Thu Jan 12 02:35:29 2023
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
:DOCKER - [0:0]
:DOCKER-ISOLATION-STAGE-1 - [0:0]
:DOCKER-ISOLATION-STAGE-2 - [0:0]
:DOCKER-USER - [0:0]
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
COMMIT
# Completed on Thu Jan 12 02:35:29 2023
# Generated by iptables-save v1.8.6 on Thu Jan 12 02:35:29 2023
*nat
:PREROUTING ACCEPT [0:0]
:INPUT ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
:DOCKER - [0:0]
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.18.0.0/16 ! -o docker0 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
COMMIT
# Completed on Thu Jan 12 02:35:29 2023
DOCKER-USER 链
-A FORWARD -j DOCKER-USER
...
-A DOCKER-USER -j RETURN
以上规则是在 filter 表中生效的:
- 第一条表示流量进入 FORWARD 链后,直接进入到 DOCKER-USER 链
- 最后一条表示流量进入 DOCKER-USER 链处理后,可以再 RETURN 回原先的链,进行后续规则的匹配。
这个其实是 Docker 预留的一个链,供用户自行配置的一些额外的规则。
Docker 默认的路由规则是允许所有客户端访问的,如果 Docker 在公网上运行,或者希望避免 Docker 中的容器被局域网中其他客户端访问,那么需要在这里添加一条规则。
iptables -I DOCKER-USER -i
! -s xxx.xxx.xxx.xxx -j DROP (仅允许 xxx.xxx.xxx.xxx 访问)
Docker 在重启之类的操作时,会进行 iptables 相关规则的清理和重建,但是 DOCKER-USER 链中的规则可以持久化,不受影响。
DOCKER-ISOLATION-STAGE-1/2 链
这两条链主要是分两个阶段进行了桥接网络隔离。
相同 network 的容器是可以 ping 通的,不同 network 的容器则不能。
Docker 链
使用最频繁,规则最多。如果误删链中内容,可能会导致容器的网络出现问题,尝试手动修改和重启Docker。
Docker 分别在 filter 和 nat 表增加了规则,具体含义如下:
filter 表中新增容器的目标地址,目标端口是映射端口的 TCP 协议被接收。
nat 表 上提供了 Docker 容器端口转发的能力,将访问本地地址端口流量的目标地址换成容器的 ip:port 地址。
containerd 与 iptables
k8s1.24不支持 dockershim,要将容器的运行时切换到 contained,在 contained 中是无法进行端口映射的。 自带的 ctr 命令不支持端口映射,那么想用的时候,怎么做呢?
一种是自己管理 iptables 规则,比较繁琐。 另一种方式是使用 nerdctl 这个专门为 containerd 做的,兼容 Docker CLI 的工具。
nerdctl run 0d –name redis -p 6379:6379 redis:alpine