技术文章
Technology
- 1: Algorithm
- 2: Kubernetes
- 2.1: k8s名词解释
- 2.2: devops
- 2.2.1: sre
- 2.3: 容器接口
- 2.4: opa
- 2.4.1: gatekeeper
- 2.5: k8s集群搭建
- 2.6: k8s集群备份
- 2.7: 审计
- 2.8: 访问apiserver
- 2.9: minio
- 2.10: cfssl 使用
- 2.11: ETCD 集群搭建
- 2.12: kind 快速搭建k8s测试集群
- 2.13: cks
- 2.14: 准入控制器
- 2.15: 容器运行时安全
- 3: Linux
- 3.1: Network
- 3.2: 内核
- 3.3: 操作系统
- 3.3.1: Alpine
- 3.3.2: Flatcar Container Linux
- 3.4: 虚拟化
- 3.4.1: Namespace
- 3.5: Systemd
- 3.6: 服务器配置 SSH 公钥登陆
- 3.7: 调度算法
- 3.8: Overlay2
- 3.9: OCI
- 3.10: tcpdump 抓包
- 3.11: 容器网络和iptables
1 - Algorithm
算法
算法的的重要性话不多说。
可以跟着 Carl 刷, 地址 。
个人认为算法最难的有:
- 回溯
- 贪心
- 动态规划
回溯
一般可以解决如下几种问题:
- 组合问题: 在N个数里面按照规则找出K个数的集合
- 切割问题: 一个字符串按照规则有几种切割方式
- 子集问题: N个数的集合里有多少符合条件的子集
- 排列问题: N个数按一定规则全排列,有几种排列方式
- 棋盘问题: N皇后,数独等
解题有固定模板,按照模板往下写。
贪心
贪心的本质是选择每一个阶段的局部最优,从而达到全局最优。 贪心算法没有固定套路模板,最好的策略就是举反例,如果想不到,就试一试贪心。 解决问题就是常识性推导加上举反例。
一般解题的4个步骤:
- 将问题分解成若干个子问题
- 找出适合的贪心策略
- 求解每一个子问题的最优解
- 将局部最优解堆叠成全局最优解
动态规划
Dynamic Programming,简称 DP 。如果某一问题有很多重叠子问题,使用动态规划是最有效的。 动态规划中每一个状态一定是由上一个状态推导出来的,这一点区别于贪心,贪心没有状态推导,而是从局部直接选出最优的。
解决的问题:
- 常见的基础问题,如斐波那契数,爬楼梯,不同路径等
- 背包问题
- 打家劫舍
- 股票问题
- 子序列问题
1.1 - 数组
数组
数组是存放在连续内存空间上的相同类型的集合。
1.1.1 - 二分查找
二分查找
二分查找
二分查找
1.给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
思路:
二分查找,注意边界问题,使用左闭右开或者左闭右闭。 在while寻找中每次的边界处理都要根据区间的定义操作。
我习惯使用 左闭右闭 区间的思路。
public int search(int[] nums, int target) {
if (nums == null || nums[0] > target || nums[nums.length - 1] < target) {
return -1;
}
int left = 0;
int right = nums.length - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (nums[mid] == target) {
return mid;
} else if (nums[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}
2.给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5
输出: 2
示例 2:
输入: nums = [1,3,5,6], target = 2
输出: 1
示例 3:
输入: nums = [1,3,5,6], target = 7
输出: 4
思路:
方法一:
直接遍历判断,变量index赋值为-1,
如果小于target,记录index,如果等于直接返回,如果大于target直接退出循环。
public int searchInsert(int[] nums, int target) {
if (nums == null) {
return -1;
}
int index = -1;
for (int i = 0; i < nums.length; i++) {
if (nums[i] < target) {
index = i;
} else if (nums[i] == target) {
return i;
} else {
break;
}
}
return index == -1 ? 0 : index + 1;
}
方法二:
二分查找,采用左闭右闭区间。
public int searchInsert(int[] nums, int target) {
if (nums == null) {
return -1;
}
int left = 0;
int right = nums.length - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (nums[mid] == target) {
return mid;
} else if (nums[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return left;
}
3.在排序数组中查找元素的第一个和最后一个位置
public int[] searchRange(int[] nums, int target) {
if (nums == null || nums.length == 0 || nums[0] > target || nums[nums.length - 1] < target) {
return new int[]{-1, -1};
}
int left = 0;
int right = nums.length - 1;
int start = -1, end = -1;
while (left <= right) {
int mid = (left + right) / 2;
if (nums[mid] == target) {
if (left == right) {
return new int[]{mid, mid};
} else {
for (int i = mid; i >= left; i--) {
if (nums[i] == target) {
start = i;
}
}
for (int i = mid; i <= right; i++) {
if (nums[i] == target) {
end = i;
}
}
return new int[]{start, end};
}
} else if (nums[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return new int[]{-1, -1};
}
1.1.2 - 移除元素
移除元素
移除元素
移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
思路: 可以使用暴力的双层循环解决,外层循环查找是否等于val值,相等时内层for循环为数值向后移动。
另一种方法是使用一层for循环,使用双指针。
- 右指针指向当前将要处理的元素
- 左指针left指向下一个将要赋值的位置
- 如果右指针指向的元素不等于val,一定是数组的一个元素,我们就将右指针指向的元素复制 到左指针位置,然后将左右指针同时右移
- 如果右指针指向的元素等于val,那么不能在输出的数组里,这时候左指针不动,右指针向右移动一位
public int removeElement(int[] nums, int val) {
int slow = 0;
for (int fast = 0; fast < nums.length; fast++) {
if (nums[fast] != val) {
nums[slow] = nums[fast];
slow++;
}
}
return slow;
}
1.2 - 树
树问题
树问题
tree
遍历方式:
- 前序
- 中序
- 后序
- 层序
属性:
- 对称
- 最大深度
- 最小深度
- 完全
- 平衡
- 所有路径
- 左子叶之和
- 左下角的值
- 路径之和
改造:
- 翻转
- 构造
- 合并
- 最大
1.3 - 回溯
回溯算法
一般是回溯的问题:
- 组合
- 分割
- 子集
- 排列
- 棋盘问题
- 其他
模板:
- 函数模板返回值和参数 返回值是void 参数一般不确定,可以先写逻辑,然后需要参数再填
- 终止条件 一般是到了叶子结点,也就是满足条件的一条答案,把这个答案存起来,并结束本层递归。 if(终止条件){ 存放结果; return; }
- 遍历过程 一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成树的深度。 for(选择:本层集合元素(树中节点孩子的数量就是集合的大小)){ 处理节点; backtracking(路径,选择列表)//递归 回溯,撤销处理结果 }
for循环可以理解是横向遍历,backtracking是纵向遍历。
分析完过程,整个框架如下:
void backtracking(参数){
if(终止条件){
存放结果;
return;
}
for(选择:本层集合元素(树中节点孩子的数量就是集合的大小)){
处理节点;
backtracking(路径,选择列表);//递归
回溯,撤销处理结果
}
}
1.4 - 动态规划
动态规划
模板
动态规划五部曲:
- 确定dp数组以及下标的定义;
- 确定递推公式
- dp数组初始化
- 确定遍历顺序
- 举例推导dp数组
2 - Kubernetes
Kubernetes
This section is where the user documentation for your project lives - all the information your users need to understand and successfully use your project.
2.1 - k8s名词解释
kubernetes 名词解释
kubernetes 名词解释
Kubernetes
先介绍一些名词和定义,方便理解演进的过程与出现的项目。
CNCF
云原生计算基金会,The Cloud Native Computing Foundation ,简称 CNCF。 作为一个厂商中立的基金会,是linxu基金会的一部分。致力于云原生应用的推广。如 kubernetes、Argo、Prometheus、Cilium等。
CNCF全景图,源地址:landscape
CNCF项目成熟度
每个项目都需要有成熟度等级,有三个级别:
- graduated(已毕业)
- incubating(孵化中)
- sandbox(初级项目)
毕业和孵化的项目被认为是稳定的,在生产环境中成功使用的。项目等级是技术委员会采用投票的方式。
云原生定义
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统做出频繁和可预测的重大变更。
什么是 kubernetes
一种流行的现代基础设施自动化的开源工具,像一个数据中心的操作系统,管理在 分布式系统 上运行的应用程序。
Kubernetes 在集群的节点上调度容器。它捆绑几个基础设施结构,如应用程序的实例、负载均衡器、持久性存储等,以一种可以被组成应用程序的方式。
2.2 - devops
devops
devops 是什么?
DevOps
DevOps 是指对企业文化、业务自动化和平台设计等方面进行全方位变革,从而实现迅捷、优质的服务交付,提升响应能力和价值。 只有通过快速迭代的服务交付,这一切才能变为现实。
DevOps 可以将传统应用和最新的云原生应用于基础架构彼此相连。
DevOps 到底是什么?
字面意思是 Devlopment(开发)和 Operations(运维)组合而成,但是它代表的理念和实践比单独或者组合的两个词广阔的多。 DevOps 涵盖了安全、协作方式、数据分析等许多方面。
2.2.1 - sre
sre
sre 是什么?
什么是SRE?
站点可靠性工程(SRE)是一种用于 IT 运维的软件工程方案。SRE团队使用软件作为工具,来管理系统、解决问题并实现运维任务自动化。
SRE 执行的任务以前通常是由运维团队手动执行,或者交给使用软件和自动化来解决问题和管理生产系统的工程师或者团队执行。
工作职责
SRE 工程师是一个独特的岗位,要么必须具备系统管理员背景、或者有运维经验的软件开发人员,要么是有软件开发经验的 IT 运维人员。
SRE 团队根据服务水平协议(SLA)确定新功能的推出,并利用服务水平指标(SLI)和服务水平目标(SLO)定义系统需要的可靠性。
SLI
提供服务水平的特定方面。关键 SLI 包括请求延迟性、可用性、错误率和系统吞吐量。
SLO
根据 SLI 而指定的服务水平的目标值或者范围。
支持 SRE 的技术
SRE 要在应用的整个生命周期中确保日常运维任务的自动化和标准化。 Ansible自动化平台 是一个全面的集成平台,可以帮助 SRE 团队实现速度、协作和增长的自动化,从而为企业的技术、 运维和财务职能提供安全性和支持。
2.3 - 容器接口
容器接口
容器开放接口
Kubernetes 作为云原生应用的基础调度平台,相当于云原生的操作系统,为了便于系统的扩展,kubernetes 中开放了以下接口,可以分别对接不同的后端,实现自己的业务逻辑:
- 容器运行时接口(CRI):提供计算资源
- 容器网络接口(CNI):提供网络资源
- 容器存储接口(CSI):提供存储资源
以上三种资源相当于一个分布式操作系统的最基础的几种资源类型,而 kubernetes 是将它们粘在一起的纽带。
2.3.1 - CRI
CRI
CRI
CRI 是一个插件接口,使 kubelet 能够使用各种容器运行时,无需重新编译集群组件。
CRI 是 kubelet 和容器运行时之间通信的主要协议。CRI 定义了 grpc 协议,用于集群组件 kubelet 与 容器运行时之间的通信。 当通过 grpc 连接到容器运行时,kubelet 充当客户端。运行时和镜像服务端点必须在容器运行时中可用。
k8s v1.24之前的 kubernetes 版本集成了 Docker Engine 的一个组件,名为 dockershim 。在v1.24之后会被移除,需要替换其他的运行时。
几种 kubernetes 常见的容器运行时:
- containerd
- CRI-O
- Docker Engine
- Mirantis Container Runtime
cgroup 驱动
在 Linux 上, CGroup 用于限制分配给进程的资源。
kubelet 和运行时都需要对接控制组来强制执行为 Pod 和容器管理资源,如CPU和Memory。如果要对接控制组,kubelet和容器运行时需要使用一个cgroup驱动。并且 kubelet 和 容器运行时需要使用相同的 cgroup 驱动和相同的配置。
可用的 cgroup 驱动有两个:
- cgroupfs
- systemd
cgroupfs 驱动
cgroupfs 驱动是 kubelet 中默认的cgroup驱动。当使用 cgroupfs 驱动时,kubelet 和容器运行时将直接对接 cgroup 文件系统来配置 cgroup。
当 systemd 是初始化系统时, 不推荐使用 cgroupfs 驱动,因为 systemd 期望系统上只有一个 cgroup 管理器。因此,如果使用 cgroup v2,则应该使用 systemd cgroup 驱动取代 cgroupfs。
systemd cgroup 驱动
当某个 Linux 系统发行版使用 systemd 作为初始化系统时,初始化进程会生成并使用一个 root 控制组(cgroup),并充当 cgroup 管理器。
注意点
当机器上有两个不同的 cgroup 管理器时,会对资源出现两个视图。如将 kublet 和 容器运行时配置为 cgroupfs,但为剩余的进程使用 systemd 的那些节点会在资源压力增大时不稳定。
containerd
配置文件: /etc/containerd/config.toml
在 Linux 上,containerd 的默认 CRI 套接字是 /run/containerd/containerd.sock。
2.3.2 - CSI
CSI
Container Storage Interface (CSI)。在 kubernetes V1.13 版本中升级为 GA 。
CSI 为容器编排系统(如 kubernetes)定义标准接口,以将任意存储系统暴露给它们的容器工作负载。
CSI 卷类型是一种 out-tree 的 CSI 卷插件,用于 Pod 与同一节点上运行的外部 CSI 卷驱动程序交互。 部署 CSI 兼容卷驱动后,用户可以使用 csi 作为卷类型来挂载驱动提供的存储。
CSI 卷可以在 Pod中以三种方式使用:
- 通过 PVC 对象引用
- 使用一般性的临时卷
- 使用 CSI临时卷,前提时驱动支持这种用法
CSI 持久卷具有以下字段可供用户指定:
- driver:一个字符串,指定要使用的卷驱动程序的名称。
- volumeHandle:一个字符串,唯一标识从 CSI 卷插件的 CreateVolume 调用返回的卷名。随后在卷驱动程序的所有后续调用中使用卷句柄来引用该卷。
- readOnly:可选的布尔值,指定卷是否被发布为只读,默认是false。
卷插件类型
树外(Out-of-Tree)卷插件
Out-of-Tree 卷插件包括容器存储接口CSI。它们使存储供应商创建自定义存储插件,而无需将插件源码添加到 kubernetes 代码仓库。
CSI 允许独立于 Kubernetes 代码库开发卷插件,并作为扩展部署(安装)在 Kubernetes 集群上。
树内(In-Tree)
以前所有的卷插件都是树内的。“树内”插件是与 Kubernetes 的核心组件一同构建、链接、编译和交付的。这意味着向 Kubernetes 添加新的存储系统(卷插件)需要将 代码合并到 kubernetes 核心代码库中。
动态配置
通过为 CSI 创建插件 StorageClass 来支持动态配置的 CSI Storage 插件启用自动创建/删除。
例如,以下允许通过名为 com.example.team/csi-driver 的 CSI Volume Plugin 动态创建 fast-storage 的 Volume。
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fast-storage
provisioner: com.example.team/csi-driver
parameters:
type: pd-ssd
要触发动态配置,需要创建一个 PersistentVolumeClaim 对象。例如,下面的 pvc 可以使用上面的 storageClass 触发动态配置。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-request-for-storage
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: fast-storage
当动态创建 Volume 时,通过 CreateVolume 调用,将参数 type: pd-ssd 传递给 CSI 插件 com.example.team/csi-driver。 作为响应,外部 volume 插件会创建一个新的 Volume,然后自动创建一个 pv 对象来对应前面的 PVC。 然后,kubernetes 会将新的 PersistentVolume 对象绑定到 pvc,使其可以使用。
创建 CSI 驱动
2.3.3 - cni
CNI
Container Network Interface(CNI)是k8s网络插件的基础。
Container Network Interface(CNI)是k8s网络插件的基础。基本思想是:Container Runtime 在创建容器时,先创建好 Network Namespace,然后再调用 CNI 插件为这个 net ns 配置网络, 其后再启动容器内的进程。
CNI插件包括两部分:
- 给容器配置网络,有两个基本的接口
- 配置网络: AddNetwork(net NetworkConfig,rt RuntimeConf)(types.Result,error)
- 清理网络: DelNetwork(net NetworkConfig,rt RuntimeConf)error
- IPAM Plugin 负责给容器分配 IP 地址,主要实现包括 host-local 和 dhcp
K8s Pod 中的其他容器都是 Pod 所属 pause 容器的网络,创建过程为:
- kubelet 创建 pause 容器生成 Network Namespace
- 调用网络 CNI driver
- CNI driver 根据配置调用具体的 CNI 插件
- CNI 插件给 pause 容器配置网络
- pod 中其他的容器都使用 pause 容器的网络
IPAM
DHCP
DHCP 插件是最主要的 IPAM 插件之一,用来通过DHCP方式给容器分配 IP 地址。
host-local
host-local 是常见的 CNI IPAM 插件,用来给 container 分配 IP 地址。
Flannel
Flannel 通过给每台宿主机分配一个子网的方式为容器提供虚拟网络,使用 UDP 封装IP 包来创建 overlay 网络,借助 etcd 维护网络的分配情况。
Calico
Calico 是一个基于 BGP 的纯三层的数据中心网络方案,不需要 Overlay。
Calico 在每个计算节点利用 Linux Kernel 实现了一个高效的 VRouter 负责数据转发,而每个 vRoute 通过 BGP 协议负责把自己上运行的 workload 的路由信息像整个 Calico 网络内传播,大规模下可以通过指定的 BGP route reflector 来完成。保证最终所有的 workload 之间的数据流量都是通过 IP 路由的方式完成互联的。
Calico 节点组网可以直接利用数据中心的网络结构,不需要额外的 NAT,隧道或者 Overlay Network。
此外,Calico 基于 iptables 提供了丰富的网络Policy。
Cilium
Cilium 是一个基于 ebpf 和 xdp 的高性能容器网络方案,提供了 CNI 和 CNM 插件。
2.3.3.1 - cilium
Cilium
Cilium
cilium路由模式
支持封装路由模式和原生路由模式。
1. 封装路由模式(overlay)
默认的路由模式,在部署时将 tunnel 设置为 vxlan 或者 geneve,它们是两种基于 UDP 的网络封装模式。 在这种模式下,所有集群节点使用基于这样的 UDP 封装协议形成的隧道网络。
2. 原生路由模式(native-routing)
将 tunnel 设置为 disabled,cilium会将所有不是发往本地另一个端点的数据包交给Linux内核的路由子系统。 如果所有的节点在同一个 L2 网络上,需要添加 auto-direct-node-routes=true,不需要额外的组件辅助。 如果节点不再同一个 L2 网络上,需要 BGP daemon 组件的辅助。
2.4 - opa
OPA 提供了一种高级声明性语言,可以将策略指定为代理和简单的API。可以将 OPA 实施在 微服务、kubernetes、CI/CD管道、API网关等中实施策略。
OPA 是一种轻量级通用策略引擎,可以与服务共处一地。可以将OPA作为 sidecar、主机级守护程序或者库进行集成。
概述
OPA 将策略指定和策略执行分开。当需要做出决策时,会查询 OPA 提供的结构化数据作为输入,OPA 接受任意结构化数据作为输入。
策略通常有:
- 允许哪些用户可以访问哪些资源
- 允许哪些子网出口流量
- 必须将工作负载部署在哪些集群
- 可以从哪些注册表二进制文件下载
- 容器可以执行哪些操作系统功能
表达式:
- 逻辑与
- and 用 ;连接在一起,也可以通过多行来省略(AND)运算符
- 不为真
变量:
- 使用赋值运算符将值存储在中间变量中 :=
s := input.servers[0]
s.id == "app"
p := s.protocols[0]
p == "https"
当 OPA 计算表达式时,会找到使所有表达式都为真的变量的值。如果没有给所有为真的变量赋值,则结果未定义。
变量是不可变的,如果尝试两次分配同一个变量。OPA会报告错误。
opa必须要能够枚举表达式总和功能所有变量的值。如果OPA无法枚举任何表达式中变量的值,则opa报错。
迭代:
- 当将变量注入表达式时,Rego中的迭代会隐式发生。
some i : input.networks[i].public == true
# 返回的 i 即为数组的下标
some i,j : input.services[i].protocols[j] == "http"
# 返回 i 和 j 的下标
some i,j
id := input.ports[i].id
public_network contians net.d if{
some net in input.networks
net.public
}
shell_accessible containers server.id if{
some server in input.servers
"telnet" in server.protocols
}
shell_accessible contians server.id if{
some server in input.servers
"ssh" in server.protocols
}
对于所有 every
no_telnet_exposed if {
every server in input.servers {
every protocol in server.portocols {
"telnet" != protocol
}
}
}
Rules
Rego 允许使用规则封装和重用逻辑。规则只是如果/那么逻辑语句,规则可以是完整的或者部分的。
完整规则
any_public_networks := true if { # head
sone net in input.networks # body
net.public
}
部分规则
public_network contains net.id if{
some net in input.networks
net.public
}
逻辑 or
input 的 servers 中只要有一个就是正确的
package example.logical_or
default shell_accessible := false
shell_accessible := true {
input.servers[_].protocols[_] == "telnet"
}
shell_accessible := true {
input.servers[_].protocols[_] == "ssh"
}
Rego
使用 Rego 定义易于读写的策略。 Rego 专注于为引用嵌套文档提供强大的支持,并确保查询正确无误。 Rego 是声明性的,因此策略作者可以专注于应该返回什么查询,而不是应该如何执行查询。这些查询比命令式语言中的等效查询更简单、更简洁。 与支持声明式查询语言的其他应用程序一样,OPA能够优化查询以提高性能。
基本语法:
- 上下文 data
- 输入 input
- 索引取值 data.bindings[0]
- 比较 alice == input.subject.user
- 赋值 user := input.subject.user
- 规则 < Header > { < Body > }
- 规则头 < Name > = < Value > { … } 或者 < Name > { … }
- 规则体 And运算的一个个描述
- 多条同名规则 Or运算的一个规则
- 规则默认值 default allow = false
- 函数 fun(x) { … }
- 虚拟文档 doc { … }
输入会挂在 input 对象下,用到的上下文会挂在data对象下。
rule: 当定义规则时:
- 每条规则都会有返回值,不声明返回值则只返回 true 或者 false,声明返回值则返回其值。
- 规则体内每条描述都会逐条 And 运算,全部成立才会返回值
- 多条同名规则相互之间是 or 运算,满足其一即可
具体到代码中规则 allow ,默认值是 false 要求 user_has_role 和 role_has_permission 同时满足,两者的 role_name 也是一样。
你可能发现,局部变量 role_name 没声明,Rego里可以省略声明局部变量,直接使用。
其中 user_has_role[role_name] 这种带参数的结构不是规则,叫虚拟文档。
2.4.1 - gatekeeper
gatekeeper
GateKeeper
OPA gatekeeper 是一个专业项目,提供 OPA 和 kubernetes 之间的一些集成。
OPA GateKeeper 在普通 OPA 之上添加了以下内容:
- 一个可扩展的参数化策略库
- 用于实例化约束的原生 CRD
- 用于扩展的策略库的云原生kubernetes CRD
Kubernetes API 服务器被分配为在创建、更新、删除对象时查询 OPA 以准入控制决策。
ApiServer 将 webhook 请求中的整个kubernetes对象发送给 OPA ,OPA 使用准入审查来评估加载的策略 input。
Input 文档包含以下字段:
- input.request.kind 类型,eg Pod,Service
- input.request.operation 操作,eg CREATE UPDATE DELETE CONNECT
- input.request.userInfo 身份信息
- input.request.object 包含完整的 kubernetes 对象
- input.request.oldObject 在操作是 UPDATE 和 DELETE 之前的object
2.5 - k8s集群搭建
k8s集群搭建
利用 kubeadm 和 二进制 两种方式搭建集群。
可以搭建单master集群,管理多个node节点。也可以使用多个master节点,管理多个node节点,同时对多个apiserver使用负载均衡。
服务器配置
一般测试环境搭建:
- master:2核 4G
- node: 4核 8G 硬盘30G
生产环境:
- master:8核 16G
- node: 8/16核 32G/64G
搭建方式
- kubeadm是一个k8s部署工具,提供 kubeadm init 和 kubeadm join,用于快速部署 kubernetes 集群。
- 二进制包方式,下载发行版包,手动部署每个组件,组成 Kubernetes 集群。
kubeadm 部署集群
kubeadm工具能够通过两条指令完成一个 kubernetes 集群的部署。
- 创建一个master节点 kubeadm init
- 将 Node 节点加入到当前集群中 kubeadm join
https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
安装要求
- 操作系统 Centos7.x
- 集群中的机器互通
- 可以访问外网,需要拉取镜像
- 禁止 swap 分区
环境准备
master: 192.168.177.130 node1: 192.168.177.131 node2: 192.168.177.132
在每台机器上执行以下命令:
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭 selinux
# 永久关闭
sed -i 's/enforcing/disabled/' /etc/selinux/config
# 临时关闭
setenforce 0
# 关闭 swap
# 永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab
# 临时关闭
swapoff -a
# 规划主机名(各个机器不同执行)
hostnamectl set-hostname k8smaster/k8snode1/k8snode2
# 添加hosts
cat >> /etc/hosts << EOF
192.168.177.130 k8smaster
192.168.177.131 k8snode1
192.168.177.132 k8snode2
EOF
# 将桥接的 Ipv4 流量传递到 iptables 的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 生效
sysctl --system
# 时间同步
yum install ntpdata -y
ntpodata time.windows.com
所有节点安装 Docker/kubeadm/kubelet
配置docker源
https://developer.aliyun.com/mirror/?spm=a2c6h.13651104.0.d1002.2cd533174OAYBv
# 使用阿里源
cat >/etc/yum.repos.d/docker.repo<<EOF
[docker-ce-edge]
name=Docker CE Edge - \$basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/\$basearch/edge
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
EOF
安装docker
# yum安装
yum -y install docker-ce
# 查看docker版本
docker --version
# 启动docker
systemctl enable docker
systemctl start docker
# 配置docker的镜像源
cat >> /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
EOF
#重启docker
systemctl restart docker
配置k8s源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装 kubeadm kubelet kubectl
# 安装kubelet、kubeadm、kubectl,同时指定版本
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
# 设置开机启动
systemctl enable kubelet
部署 kubernetes master node
kubeadm init --apiserver-advertise-address=192.168.177.130 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.18.0 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
当出现 successfully 字样时表示已经安装成功。最下面有工作节点添加进集群的命令,需要copy。
#使用 kubectl 工具
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 检查,会发现有一个master节点,但是状态是 NotReady
kubectl get nodes
部署 kubernetes worker node
复制 kubeadm init … 输出的 kubeadm join 命令执行。默认 token 的有效期是 24h,当过期之后需要重新创建token。
kubeadm token create --print-join-command
当我们把两个节点都加入进来后,可以去 master 节点执行下面命令:
# 出现三个节点,但是状态都是 NotReady
kubectl get node
部署 CNI 网络插件
# 下载网络插件配置,需要修改镜像
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# apply 一下创建,之后会发现已经 Ready
# 如果还是有些节点处于 NotReady 状态,可以在master节点删除该节点,然后节点重置之后重新加入。
kubectl delete node k8snode1
#在 k8snode1 节点上进行重置
kubeadm reset
# 重置完成后加入
kubeadm join 192.168.177.130:6443 --token 8j6ui9.gyr4i156u30y80xf --discovery-token-ca-cert-hash sha256:eda1380256a62d8733f4bddf926f148e57cf9d1a3a58fb45dd6e80768af5a500
二进制搭建 1.24
两台机器,vms71和vms72
系统centos7.4
- vms71为 master
- vms72 为 worker
基本设置
识别地址
cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.26.71 vms71.rhce.cc vms71
192.168.26.72 vms72.rhce.cc vms72
关闭swap分区
swapoff -a ; sed -i '/fstab/d' /etc/fstab
更新 yum 源
rm -rf /etc/yum.repos.d/* ; wget ftp://ftp.rhce.cc/k8s/* -P /etc/yum.repos.d/ #一般更新为阿里源
yum clean all
安装 containerd
yum install containerd.io cri-tools -y
crictl config runtime-endpoint unix:///var/run/containerd/containerd.sock
先生成配置文件/etc/containerd/config.toml
containerd config default > /etc/containerd/config.toml
编辑配置文件,改成:
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://frz7i079.mirror.aliyuncs.com"]
# 修改 sandbox_image
[plugins."io.containerd.grpc.v1.cri"]
# enable SELinux labeling
enable_selinux = true
sandbox_image = "XX/pause:3.6"
# 根据cgroup版本配置是否为true
SystemdCgroup = false
在所有节点重启 containerd ,并设置开机自动启动
systemctl enable containerd
systemctl restart containerd
在所有机器上执行命令,目的是系统重启时能自动加载。
cat > /etc/modules-load.d/containerd.conf <<EOF
overlay
br_netfilter
EOF
执行以下内核命令
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf
安装 nerdctl(containerd cli,可选) https://github.com/containerd/nerdctl/releases https://github.com/containernetworking/plugins/releases
修改环境配置文件
vim /etc/profile
#添加
source <(nerdctl completion bash)
export CONTAINERD_NAMESPACE=k8s.io
# 生效
source /etc/profile
安装 cfssl 工具,放在 /usr/local/bin 中。
# ls
cfssl-certinfo_linux-amd64 cfssljson_linux-amd64 cfssl_linux-amd64
#for i in *;do n=${i%_*};mv $i $n;done;chmod +x *
# ls
cfssl cfssl-certinfo cfssljson
# 移动到 /usr/local/bin 文件夹
配置 k8s 各组件所需要的证书
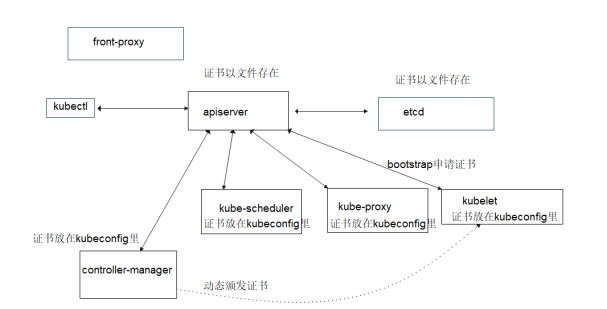
操作在一个机器上操作,然后将生成的正式拷贝到 /etc/kubernetes/pki 里。
mkdir -p /etc/kubernetes/pki
搭建CA
# cfssl print-defaults config > ca-config.json
# cat ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
# cfssl print-defaults csr > ca-csr.json
# cat ca-csr.json
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "Shanxi",
"L": "xian",
"O": "kubernetes",
"OU": "system"
}
]
}
# cfssl gencert -initca ca-csr.json |cfssljson -bare ca
# ls
ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem
front-proxy-ca
创建聚合层(Aggregation Layer)所需要的证书,如果环境里没有配置聚合层,这步和下步创建证书的步骤是不需要的。
生成 front-proxy-ca 自签名证书
cp ca-config.json front-proxy-ca-config.json
cp ca-csr.json front-proxy-ca-csr.json
cfssl gencert -initca front-proxy-ca-csr.json | cfssljson -bare front-proxy-ca
聚合层客户端证书
cfssl print-defaults csr > front-proxy-client-csr.json
{
"CN": "front-proxy-client",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "Shanxi",
"L": "XIan",
"O": "kubernetes",
"OU": "system"
}
]
}
cfssl gencert -ca=front-proxy-ca.pem -ca-key=front-proxy-ca-key.pem -config=front-proxy-ca-config.json -profile=www front-proxy-client-csr.json | cfssljson -bare front-proxy-client
etcd 证书
etcd需要跟apiserver进行双向tls认证,etcd服务器端需要证书和私钥,先创建etcd证书请求文件。
先创建etcd服务端证书
cfssl print-defaults csr > etcd-csr.json
{
"CN": "etcd",
"key": {
"algo": "rsa",
"size": 2048
},
"hosts": [
"127.0.0.1",
"192.168.26.71",
"xxx"
],
"names": [
{
"C": "CN",
"ST": "Shanxi",
"L": "Xian",
"O": "kubernetes",
"OU": "system"
}
]
}
# 颁发 etcd 服务器端所需要的证书
cfssl gencert -ca-ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www etcd-csr.json | cfssljson -bare etcd
ls etcd*.pem
etcd-key.pem etcd.pem
再创建 etcd客户端证书,当 apiserver向 etcd 连接时向etcd出示的证书
cfssl print-defaults csr > etcd-client-csr.json
cat etcd-client-csr.json
{
"CN": "etcd",
"key": {
"algo": "rsa",
"size": 2048
},
"hosts": [
"127.0.0.1",
"192.168.26.71",
"xxx"
],
"names": [
{
"C": "CN",
"ST": "Shanxi",
"L": "Xian",
"O": "kubernetes",
"OU": "system"
}
]
}
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www etcd-client-csr.json | cfssljson -bare etcd-client
ls etcd-client*.pem
etcd-clinet-key.pem etcd-client.pem
Apiserver 证书
k8s其他组件要跟 apiserver进行双向tls认证,所以apiserver需要自己的证书,下面生成apiserver所需要的证书请求文件。
cfssl print-defaults csr > apiserver-csr.json
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"hosts": [
"127.0.0.1",
"192.168.26.71", # master节点的Ip填上
"192.168.26.72",
"10.96.0.1", # service网络的第一个ip
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"names": [
{
"C": "CN",
"ST": "Shanxi",
"L": "Xian",
"O": "kubernetes",
"OU": "system"
}
]
}
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www apiserver-csr.json | cfssljson -bare apiserver
ls apiserver*.pem
apiserver-key.pem apiserver.pem
controller-manager
controller-manager 需要跟apiserver 进行 mtls 认证,生成证书申请请求文件
cfssl print-defaults csr > controller-manager-csr.json
{
"CN": "system:kube-controller-manager",
"key": {
"algo": "rsa",
"size": 2048
},
"hosts": [
"127.0.0.1",
"192.168.26.71" # 所有 节点ip
],
"names": [
{
"C": "CN",
"ST": "Shanxi",
"L": "Xian",
"O": "system:kube-controller-manager",
"OU": "system"
}
]
}
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www controller-manager-csr.json | cfssljson -bare controller-manager
ls -1 control*.pem
controller-manager-key.pem controller-manager.pem
schedule 也用相同的方式,kube-proxy 也用相同的方式(没有host)
admin 用到的证书
cfssl print-defaults csr > admin-csr.json
cat admin-csr.json
{
"CN": "admin",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "Jiangsu",
"L": "Xuzhou",
"O": "system:masters",
"OU": "system"
}
]
}
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www admin-csr.json | cfssljson -bare admin
把所有证书都拷贝到 /etc/kubernetes/pki 里。
$ ls /etc/kubernetes/pki
admin-key.pem ca-key.pem etcd-client-key.pem front-proxy-ca-key.pem proxy-key.pem admin.pem ca.pem etcd-client.pem front-proxy-ca.pem proxy.pem
apiserver-key.pem controller-manager-key.pem etcd-key.pem front-proxy-client-key.pem scheduler-key.pem
apiserver.pem controller-manager.pem etcd.pem front-proxy-client.pem scheduler.pem
etcd 安装
下载地址 https://github.com/etcd-io/etcd/releases/download/v3.5.4/etcd-v3.5.4-linux-amd64.tar.gz 将下载后的可执行文件拷贝到 /usr/local/bin 目录下。
创建两个目录
mkdir /etc/etcd /var/lib/etcd
配置文件
cat /etc/etcd/etcd.conf
#[Member]
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.26.71:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.26.71:2379,http://127.0.0.1:2379"
ETCD_NAME="etcd1"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.26.71:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.26.71:2379"
ETCD_INITIAL_CLUSTER="etcd1=https://192.168.26.71:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
创建etcd的启动脚本。 /usr/lib/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=-/etc/etcd/etcd.conf
WorkingDirectory=/var/lib/etcd/
ExecStart=/usr/local/bin/etcd \
--cert-file=/etc/kubernetes/pki/etcd.pem \
--key-file=/etc/kubernetes/pki/etcd-key.pem \
--trusted-ca-file=/etc/kubernetes/pki/ca.pem \
--peer-cert-file=/etc/kubernetes/pki/etcd.pem \
--peer-key-file=/etc/kubernetes/pki/etcd-key.pem \
--peer-trusted-ca-file=/etc/kubernetes/pki/ca.pem \
--peer-client-cert-auth \
--client-cert-auth
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
启动etcd并设置开机自启
systemctl enable etcd --now
systemctl is-actiive etcd
配置 kubernetes 各个组件
下载对应的二进制包,解压到对应的目录。如:/usr/bin/
后面配置 kubelet 的 bootstrap 认证,即 kubelet 启动时自动创建 csr 请求,这里需要在 apiserver 上开启 token 的认证,所以现在master上生成一个随机值作为token。
openssl rand -hex 10
xxxxxxxxx
将token导入到文件里,这里写入到 /etc/kubernetes/token.csv,格式为 token,user,uid,groups
xxxxxxxxx,kubelet-bootstrap,10001,"system:node-bootstrapper"
创建 apiserver 启动脚本:
cat /usr/lib/systemd/system/kube-apiserver.service
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=/usr/bin/kube-apiserver \
--v=2 \
--logtostderr=true \
--allow-privileged=true \
--bind-address=192.168.26.71 \
--secure-port=6443 \
--token-auth-file=/etc/kubernetes/token.csv \
--advertise-address=192.168.26.71 \
--service-cluster-ip-range=10.96.0.0/16 \
--service-node-port-range=30000-60000 \
--etcd-servers=https://192.168.26.71:2379 \
--etcd-cafile=/etc/kubernetes/pki/ca.pem \
--etcd-certfile=/etc/kubernetes/pki/etcd.pem \
--etcd-keyfile=/etc/kubernetes/pki/etcd-key.pem \
--client-ca-file=/etc/kubernetes/pki/ca.pem \
--tls-cert-file=/etc/kubernetes/pki/apiserver.pem \
--tls-private-key-file=/etc/kubernetes/pki/apiserver-key.pem \
--kubelet-client-certificate=/etc/kubernetes/pki/apiserver.pem \
--kubelet-client-key=/etc/kubernetes/pki/apiserver-key.pem \
--service-account-key-file=/etc/kubernetes/pki/ca-key.pem \
--service-account-signing-key-file=/etc/kubernetes/pki/ca-key.pem \
--service-account-issuer=https://kubernetes.default.svc.cluster.local \
--kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname \
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota \
--authorization-mode=Node,RBAC \
--enable-bootstrap-token-auth=true
#--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \
#--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.pem \
#--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client-key.pem \
#--requestheader-allowed-names=aggregator \
#--requestheader-group-headers=X-Remote-Group \
#--requestheader-extra-headers-prefix=X-Remote-Extra- \
#--requestheader-username-headers=X-Remote-User
Restart=on-failure
RestartSec=10s
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target
几个选项作用:
- –v 日志等级
- –enable-bootstrap-token-auth :启用 tls bootstrap 机制
- –token-auth-file :bootstrap token 文件
启动 apiserver
systemctl start kube-apiserver
systemctl enable kube-apiserver
配置 controller-manager
cat /usr/lib/systemd/system/kube-controller-manager.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=/usr/bin/kube-controller-manager \
--v=2 \
--logtostderr=true \
--bind-address=127.0.0.1 \
--root-ca-file=/etc/kubernetes/pki/ca.pem \
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem \
--cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem \
--service-account-private-key-file=/etc/kubernetes/pki/ca-key.pem \
--kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \
--leader-elect=true \
--use-service-account-credentials=true \
--node-monitor-grace-period=40s \
--node-monitor-period=5s \
--pod-eviction-timeout=2m0s \
--controllers=*,bootstrapsigner,tokencleaner \
--allocate-node-cidrs=true \
--cluster-cidr=10.244.0.0/16 \
--node-cidr-mask-size=24
Restart=always
RestartSec=10s
[Install]
WantedBy=multi-user.target
创建 controller-manager 所需要的 kubeconfig 文件 – kube-controller-manager.kubeconfig
controller-manager 和 apierver 之间的认证是通过 kubeconfig 的方式来认证的,即 controller-manager 的私钥,公钥,ca的证书放在一个 kubeconfig 文件里。 下面创建 controller-manager 所用的 kubeconfig 文件 kube-controller-manager.kubeconfig
cd /etc/kubernetes/pki/
# 设置集群信息
kubectl config set-cluster kubernetes --certificate-authority=ca.pem --embed-certs=true --server=https://192.168.26.71:6443 --kubeconfig=kube-controller-manager.kubeconfig
# 设置用户信息
kubectl config set-credentials system:kube-controller-manager --client-certificate=controller-manager.pem --client-key=controller-manager-key.pem --embed-certs=true --kubeconfig=kube-controller-manager.kubeconfig
# 设置上下文信息
kubectl config set-context system:kube-controller-manager --cluster=kubernetes --user=system:kube-controller-manager --kubeconfig=kube-controller-manager.kubeconfig
# 设置默认的上下文
kubectl config use-context system:kube-controller-manager --kubeconfig=kube-controller-manager.kubeconfig
#放到合适的地方
mv kube-controller-manager.kubeconfig /etc/kubernetes/
启动和开机自启
systemctl deamon-reload
systemctl enable kube-controller-manager --now
systemctl start kube-controller-manager
配置和启动 scheduler
cat /usr/lib/systemd/system/kube-scheduler.service
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=/usr/bin/kube-scheduler \
--v=2 \
--logtostderr=true \
--bind-address=127.0.0.1 \
--leader-elect=true \
--kubeconfig=/etc/kubernetes/kube-scheduler.kubeconfig
Restart=always
RestartSec=10s
[Install]
WantedBy=multi-user.target
创建scheduler 的 kubeconfig 和启动参考上文。
最后创建admin能用的kubeconfig
- 注意用户是admin,其他都一样,参考上文。
kubelet 为用户 kubelet-bootstrap 授权,允许 kubelet tls bootstrap 创建 CSR 请求。
kubectl create clusterrolebinding kubelet-bootstrap1 --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
把 system:certificates.k8s.io:certificatesigningrequests:nodeclient 授权给 kubelet-bootstrap ,目的是为了实现对 csr 的自动审批。
kubectl create clusterrolebinding kubelet-bootstrap2 --clusterrole=system:certificates.k8s.io:certificatesigningrequests:nodeclient --user=kubelet-bootstrap
创建 kubelet bootstap 的 kubeconfig 文件。
- 用户名是 kube-bootstrap
- 用指定的token –token
创建启动脚本 ,后面会把 kubelet 颁发的证书放在 /var/lib/kubelet/pki 里,所以先把此目录创建出来。
mkdir -p /var/lib/kubelet/pki /var/log/kubernetes
cat /usr/lib/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/kubernetes/kubernetes
After=containerd.service
Requires=containerd.service
[Service]
WorkingDirectory=/var/lib/kubelet
ExecStart=/usr/bin/kubelet \
--bootstrap-kubeconfig=/etc/kubernetes/kubelet-bootstrap.conf \
--cert-dir=/var/lib/kubelet/pki \
--kubeconfig=/etc/kubernetes/kubelet.kubeconfig \
--config=/etc/kubernetes/kubelet-config.yaml \
--pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7 \
--container-runtime=remote \
--container-runtime-endpoint=unix:///var/run/containerd/containerd.sock \
--runtime-request-timeout=15m \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/var/log/kubernetes \
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
创建 kubelet 用的配置文件 kubelet-config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
address: 0.0.0.0
port: 10250
readOnlyPort: 10255
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
这里指定的 cluster dns 的ip是 10.96.0.10
最后将kubelet 能用到的文件同步到所有的worker节点上,启动kubelet并设置开机自启。
查看 csr已经有申请请求自动审批了。
安装 kube-proxy
kube-proxy.yaml
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
clientConnection:
kubeconfig: /etc/kubernetes/kube-proxy.kubeconfig
clusterCIDR: 10.244.0.0/16
kind: KubeProxyConfiguration
metricsBindAddress: 0.0.0.0:10249
mode: "ipvs"
再创建一个 kubeconfig 同上
[Unit]
Description=Kubernetes Kube-Proxy Server
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
WorkingDirectory=/var/lib/kube-proxy
ExecStart=/usr/bin/kube-proxy \
--config=/etc/kubernetes/kube-proxy.yaml \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/var/log/kubernetes \
--v=2
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
rbac
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kubernetes-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
verbs:
- "*"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kubernetes
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kubernetes-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kubernetes
安装网络插件,部署coredns,最后测试.
2.6 - k8s集群备份
k8s集群备份
使用 velero 进行k8s集群和持久卷的备份、迁移和灾难恢复。
安装
可以使用 velero cli 或者 helm 进行安装。
- https://github.com/heptio/velero/releases
- https://velero.io/
- https://vmware-tanzu.github.io/helm-charts/
启动 velero ,创建定期备份,一般每天凌晨备份一次,可以忽略持久化备份。
2.7 - 审计
(k8s集群审计)[https://kubernetes.io/zh-cn/docs/tasks/debug/debug-cluster/audit/#audit-policy]
Kubernetes 审计(Audit)提供了安全相关的时序操作记录,支持 日志 和 webhook 两种格式,并可以通过审计策略自定义事件类型。
kubernetes 审计功能提供了与安全相关的、按照事件顺序排列的记录集,记录每个用户、使用 kubernetes API 的应用以及控制面自身引发的活动。
审计记录最初产生于 kube-apiserver 内部,每个请求在不同阶段都会生成审计事件,这些事件会根据特定策略被预处理并写入后端。 策略确定要记录的内容和用来存储记录的后端。
每个请求都可被记录其相关的阶段(stage),已定义的阶段有:
- RequestReceived 审计处理器接收到请求后,并且在委托给其余处理器之前发生的事件。
- ResponseStarted 在响应消息的头部发送后,响应消息体发送前发生的事件。只有长时间运行的请求(例如 watch) 才会有这个阶段
- ResponseComplete 在响应消息体完成并且没有更多数据需要传输的时候。
- Panic 当 panic 发生时生成
审计策略:
审计策略定义了相关应记录哪些事件以及哪些数据的规则。审计策略对象结构定义在 audit.k8s.io API组。处理事件时,按照顺序与规则列表进行比较。
第一个匹配规则设置事件的 审计级别(Audit Level)。已定义的审计级别有:
- None 符合这条规则的日志将不会记录
- Metadata 记录请求的元数据,但没有消息体
- Request 记录事件的元数据和请求的消息体,但是不记录响应的消息体
- RequestResponse 记录事件的元数据,请求和响应的消息体,不适用于非资源类型请求
使用 –audit-policy-file 参数指定策略,传递给 kube-apiserver 。如果不设置该标志,则不记录事件。 注意 rules 字段必须在审计策略文件中提供,没有规则的策略将被视为非法配置。
审计日志 Log 后端
配置 kube-apiserver 的参数开启审计日志。
- audit-log-format:日志格式
- audit-log-path:审计日志路径
- audit-log-maxage:旧日志最长保留天数
- audit-log-maxbackup:旧日志文件最长保留个数
- audit-log-maxsize:日志文件最大大小(单位MB),超过后自动做轮转(默认为100MB)
eg:
--audit-log-format=json
--audit-log-maxage=30
--audit-log-maxbackup=10
--audit-log-maxsize=100
--audit-log-path=/var/log/audit/kube-audit.log
--audit-policy-file=/etc/kubernetes/policies/audit-policy.yaml
eg:
{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"5737a616-9f5a-4efe-98f8-90f5b1b56880","stage":"ResponseComplete","requestURI":"/api/v1/namespaces/default/configmaps/console-operator-lock","verb":"get","user":{"username":"system:serviceaccount:default:default-sa","uid":"1640a9e4-eef5-4b39-8d6d-871fef41107b","groups":["system:serviceaccounts","system:serviceaccounts:default","system:authenticated"],"extra":{"authentication.kubernetes.io/pod-name":["console-operator-7bd67974fd-bvxf4"],"authentication.kubernetes.io/pod-uid":["275b6b2a-f58f-4443-8544-e277c24138a0"]}},"sourceIPs":["10.222.8.92"],"userAgent":"console-operator/v0.0.0 (linux/amd64) kubernetes/$Format/leader-election","objectRef":{"resource":"configmaps","namespace":"default","name":"console-operator-lock","apiVersion":"v1"},"responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2023-04-06T01:57:25.529046Z","stageTimestamp":"2023-04-06T01:57:25.538347Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"default-sa\" of ClusterRole \"default-sa\" to ServiceAccount \"default-sa/default\""}}
2.8 - 访问apiserver
如何访问apiserver?
1. 在集群外访问apiserver
1. kubectl 访问 apiserver
默认配置在 $HOME/.kube/config ,或者指定配置文件 kubectl –kubeconfig 。
可以使用环境变量 KUBECONFIG 。
--v=0 Generally useful for this to ALWAYS be visible to an operator.
--v=1 A reasonable default log level if you don’t want verbosity.
--v=2 Useful steady state information about the service and important log messages that may correlate to significant changes in the system. This is the recommended default log level for most systems.
--v=3 Extended information about changes.
--v=4 Debug level verbosity.
--v=6 Display requested resources.
--v=7 Display HTTP request headers.
--v=8 Display HTTP request contents
2.curl 访问 apiserver
# 1. 获取token
cat << EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: custome-sa
namespace: default
---
apiVersion: v1
kind: Secret
metadata:
name: custome-sa
namespace: default
annotations:
kubernetes.io/service-account.name: "custome-sa"
namespace: default
type: kubernetes.io/service-account-token
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: sa-crb
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: custome-sa
namespace: default
EOF
TOKEN=`kubectl get secret custome-sa --template={{.data.token}} | base64 --decode`
echo $TOKEN
#2. 直接访问
curl --insecure -H "Authorization: Bearer $TOKEN" https://xxx:443/api/v1/namespaces/default/services
# 或者可以使用本地代理访问
kubectl proxy --port 8080
curl --insecure -H "Authorization: Bearer $TOKEN" https://127.0.0.1:8080/api/v1/namespaces/default/services
2. 集群内访问 apiserver
在 Pod 内通过 serviceaccount 内访问。
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: custome-sa
namespace: default
---
apiVersion: v1
kind: Secret
metadata:
name: custome-sa
annotations:
kubernetes.io/service-account.name: "custome-sa"
namespace: default
type: kubernetes.io/service-account-token
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: pods-list
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["list"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: pods-list
subjects:
- kind: ServiceAccount
name: custome-sa
namespace: default
roleRef:
kind: ClusterRole
name: pods-list
apiGroup: rbac.authorization.k8s.io
EOF
TOKEN=`kubectl get secret custome-sa --template={{.data.token}} | base64 --decode`
echo $TOKEN
# 创建工作负载时指定sa
spec:
serviceAccountName: custome-sa
# 在 pod 内访问
export CURL_CA_BUNDLE=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt
TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
curl -H "Authorization: Bearer $TOKEN" https://kubernetes
3. Client-go 访问 api
- RestClient 客户端 对httpclient的封装
- ClientSet 客户端 仅支持内置资源(最常用)
- DynamicClient 客户端 支持内置资源 + crd
- DiscoveryClient 客户端
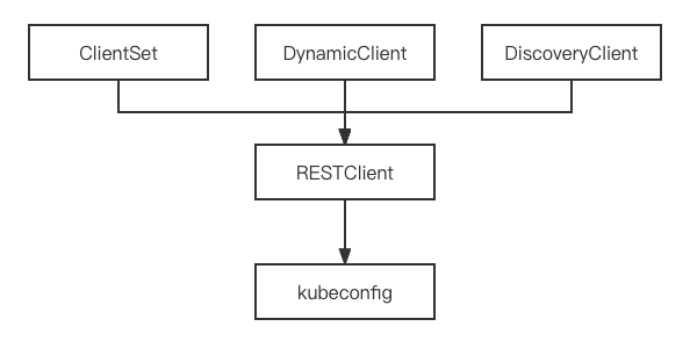
Client-go 目录结构:
- discovery: 提供 DisconveryClient 发现客户端。
- dynamic: 提供 DynamicClient 发现客户端。
- kubernetes: 提供 ClientSet 客户端。
- rest: 提供 RESTClient 发现客户端。
- informers: 每种 Kubernetes 资源的 Informer 实现。
- listers: 为每一个 Kubernetes 资源提供 Lister 功能,提供只读缓存数据。
- plugin: 提供云服务商授权插件。
- scale: 提供 ScaleClient 发现客户端。
- tools: 提供常用工具。
- transport: 提供安全的 TCP 连接。
- util: 提供常用方法。
2.9 - minio
企业级开源的对象存储。
客户端操作
一般使用客户端命令进行备份操作。
# 添加远程,需要 access key
mc config host add my-minio https://xxx --api S3v4
# 上传
mc cp {local/path} my-minio/backup/ #可以用 * 上传目录下所有的文件
# 下载所有backup backut下的文件到本地当前目录
mc cp --recursive my-minio/backup .
# 查看所有的bucket
mc ls my-minio
NAME:
mc - MinIO Client for cloud storage and filesystems.
USAGE:
mc [FLAGS] COMMAND [COMMAND FLAGS | -h] [ARGUMENTS...]
COMMANDS:
alias set, remove and list aliases in configuration file
ls list buckets and objects
mb make a bucket
rb remove a bucket
cp copy objects
mirror synchronize object(s) to a remote site
cat display object contents
head display first 'n' lines of an object
pipe stream STDIN to an object
share generate URL for temporary access to an object
find search for objects
sql run sql queries on objects
stat show object metadata
mv move objects
tree list buckets and objects in a tree format
du summarize disk usage recursively
retention set retention for object(s)
legalhold manage legal hold for object(s)
diff list differences in object name, size, and date between two buckets
rm remove objects
version manage bucket versioning
ilm manage bucket lifecycle
encrypt manage bucket encryption config
event manage object notifications
watch listen for object notification events
undo undo PUT/DELETE operations
policy manage anonymous access to buckets and objects
tag manage tags for bucket and object(s)
replicate configure server side bucket replication
admin manage MinIO servers
update update mc to latest release
GLOBAL FLAGS:
--autocompletion install auto-completion for your shell
--config-dir value, -C value path to configuration folder (default: "/root/.mc")
--quiet, -q disable progress bar display
--no-color disable color theme
--json enable JSON lines formatted output
--debug enable debug output
--insecure disable SSL certificate verification
--help, -h show help
--version, -v print the version
TIP:
Use 'mc --autocompletion' to enable shell autocompletion
VERSION:
RELEASE.2021-03-23T05-46-11Z
2.10 - cfssl 使用
启用加密,防止流量拦截和中间人攻击。
1. 下载 cfssl
在github上的 cfssl源码和下载地址 。
mkdir ~/bin
curl -s -L -o ~/bin/cfssl https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
curl -s -L -o ~/bin/cfssljson https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
curl -s -L -o ~/bin/cfssl-certinfo https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x ~/bin/{cfssl,cfssljson,cfssl-certinfo}
# 临时生效
export PATH=$PATH:~/bin
# 写到文件中 export PATH=$PATH:/root/bin
source /etc/profile
2. 初始化CA证书
mkdir ~/cfssl
cd ~/cfssl
cfssl print-defaults config > ca-config.json
cfssl print-defaults csr > ca-csr.json
以生成 kubernetes 或者 etcd 自签证书为例:
配置 CA 信息
一般来说,profiles 节点有多个配置,server端证书带有 server auth ,client端证书带有 client auth ,peer 端的证书需要 server auth 和 client auth。时间默认值为 8760h
"profiles": {
"server": {
"expiry": "8760h",
"usages": [
"signing",
"key encipherment",
"server auth"
]
},
"client": {
"expiry": "8760h",
"usages": [
"signing",
"key encipherment",
"client auth"
]
},
"peer": {
"expiry": "8760h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
这里为了简单只用一个 profile ,服务端,客户端,peer 公用一个证书。 ca-cofnig.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"etcd": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
ca-csr.json
{
"CN": "etcd",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "US",
"L": "CA",
"ST": "San Francisco",
"O": "Etcd"
}
]
}
生成 CA
cfssl gencert -initca ca-csr.json |cfssljson -bare ca-etcd -
执行完成后得到以下文件
ca-etcd-key.pem
ca-etcd.csr
ca-etcd.pem
- ca-etcd-key.pem 妥善保管此文件,此密钥允许在CA内创建任何类型的证书
3. 生成 server 端证书
cfssl print-defaults csr > etcd-server.json
服务器证书最重要的值是 CN 和 hosts,必须替换它们。
...
"CN": "etcd1",
"hosts": [
"192.168.122.68",
"etcd.example.com",
"etcd1"
],
...
生成 server 证书和私钥:
cfssl gencert -ca-ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=etcd etcd-server.json | cfssljson -bare cert-etcd-server
将生成以下文件:
cert-etcd-server-key.pem
cert-etcd-server.csr
cert-etcd-server.pem
4. 生成对等证书
cfssl print-defaults csr > member1.json
替换 CN 和 hosts 。
...
"CN": "member1",
"hosts": [
"192.168.122.101",
"member1.example.com",
"member1"
],
...
生成 member1 的证书和私钥:
cfssl gencert -ca-ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=etcd member1.json | cfssljson -bare cert-member1
5. 生成客户端证书
cfssl print-defaults csr > client.json
客户端证书,可以忽略 hosts ,仅将 CN 设置为客户端值。
...
"CN": "client",
...
生成 client 的证书和私钥:
cfssl gencert -ca-ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=etcd client.json | cfssljson -bare client
6. 验证数据
openssl x509 -in ca.pem -text -noout
openssl x509 -in server.pem -text -noout
openssl x509 -in client.pem -text -noout
7. 注意点
- 将 ca-key.pem 存储在安全的地方
- 确保文件安全,设置适当的文件权限。 chmod 0600 server-key.pem
- 为通配符地址,可以工作在任何机器上,简化证书流程,但是会增加安全风险。
2.11 - ETCD 集群搭建
ETCD 集群搭建
最主要的还是阅读官方文档,下面演示一些操作。生成证书可以参考上面 cfssl使用 文章。
下面演示在一个节点起三个etcd节点。
1.没有 TLS
etcd --name etcd1 \
--data-dir /root/etcd/etcd1 \
--initial-advertise-peer-urls http://172.31.239.82:12380 \
--listen-peer-urls http://172.31.239.82:12380 \
--listen-client-urls http://172.31.239.82:12379,http://127.0.0.1:12379 \
--advertise-client-urls http://172.31.239.82:12379 \
--initial-cluster-token token \
--initial-cluster etcd1=http://172.31.239.82:12380,etcd2=http://172.31.239.82:22380,etcd3=http://172.31.239.82:32380 \
--initial-cluster-state new
etcd --name etcd2 \
--data-dir /root/etcd/etcd2 \
--initial-advertise-peer-urls http://172.31.239.82:22380 \
--listen-peer-urls http://172.31.239.82:22380 \
--listen-client-urls http://172.31.239.82:22379,http://127.0.0.1:22379 \
--advertise-client-urls http://172.31.239.82:22379 \
--initial-cluster-token token \
--initial-cluster etcd1=http://172.31.239.82:12380,etcd2=http://172.31.239.82:22380,etcd3=http://172.31.239.82:32380 \
--initial-cluster-state new
etcd --name etcd3 \
--data-dir /root/etcd/etcd3 \
--initial-advertise-peer-urls http://172.31.239.82:32380 \
--listen-peer-urls http://172.31.239.82:32380 \
--listen-client-urls http://172.31.239.82:32379,http://127.0.0.1:32379 \
--advertise-client-urls http://172.31.239.82:32379 \
--initial-cluster-token token \
--initial-cluster etcd1=http://172.31.239.82:12380,etcd2=http://172.31.239.82:22380,etcd3=http://172.31.239.82:32380 \
--initial-cluster-state new
cd etcd/ssl
etcdctl --endpoints=http://172.31.239.82:12379 member list -w table
etcdctl --endpoints=http://172.31.239.82:12379 endpoint status -w table --cluster
2. 有 TLS
rm -fr /root/etcd/etcd1/*
etcd --name etcd1 \
--data-dir /root/etcd/etcd1 \
--initial-advertise-peer-urls https://172.31.239.82:12380 \
--listen-peer-urls https://172.31.239.82:12380 \
--listen-client-urls https://172.31.239.82:12379,https://127.0.0.1:12379 \
--advertise-client-urls https://172.31.239.82:12379 \
--initial-cluster-token token \
--initial-cluster etcd1=https://172.31.239.82:12380,etcd2=https://172.31.239.82:22380,etcd3=https://172.31.239.82:32380 \
--initial-cluster-state new \
--client-cert-auth \
--peer-client-cert-auth \
--trusted-ca-file "/root/etcd/ssl/ca-etcd.pem" \
--cert-file "/root/etcd/ssl/cert-etcd.pem" \
--key-file "/root/etcd/ssl/cert-etcd-key.pem" \
--peer-trusted-ca-file "/root/etcd/ssl/ca-etcd.pem" \
--peer-cert-file "/root/etcd/ssl/cert-etcd.pem" \
--peer-key-file "/root/etcd/ssl/cert-etcd-key.pem" \
--cipher-suites "TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_AES_256_GCM_SHA384"
rm -fr /root/etcd/etcd2/*
etcd --name etcd2 \
--data-dir /root/etcd/etcd2 \
--initial-advertise-peer-urls https://172.31.239.82:22380 \
--listen-peer-urls https://172.31.239.82:22380 \
--listen-client-urls https://172.31.239.82:22379,https://127.0.0.1:22379 \
--advertise-client-urls https://172.31.239.82:22379 \
--initial-cluster-token token \
--initial-cluster etcd1=https://172.31.239.82:12380,etcd2=https://172.31.239.82:22380,etcd3=https://172.31.239.82:32380 \
--initial-cluster-state new \
--client-cert-auth \
--peer-client-cert-auth \
--trusted-ca-file "/root/etcd/ssl/ca-etcd.pem" \
--cert-file "/root/etcd/ssl/cert-etcd.pem" \
--key-file "/root/etcd/ssl/cert-etcd-key.pem" \
--peer-trusted-ca-file "/root/etcd/ssl/ca-etcd.pem" \
--peer-cert-file "/root/etcd/ssl/cert-etcd.pem" \
--peer-key-file "/root/etcd/ssl/cert-etcd-key.pem" \
--cipher-suites "TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_AES_256_GCM_SHA384"
rm -fr /root/etcd/etcd3/*
etcd --name etcd3 \
--data-dir /root/etcd/etcd3 \
--initial-advertise-peer-urls https://172.31.239.82:32380 \
--listen-peer-urls https://172.31.239.82:32380 \
--listen-client-urls https://172.31.239.82:32379,https://127.0.0.1:32379 \
--advertise-client-urls https://172.31.239.82:32379 \
--initial-cluster-token token \
--initial-cluster etcd1=https://172.31.239.82:12380,etcd2=https://172.31.239.82:22380,etcd3=https://172.31.239.82:32380 \
--initial-cluster-state new \
--client-cert-auth \
--peer-client-cert-auth \
--trusted-ca-file "/root/etcd/ssl/ca-etcd.pem" \
--cert-file "/root/etcd/ssl/cert-etcd.pem" \
--key-file "/root/etcd/ssl/cert-etcd-key.pem" \
--peer-trusted-ca-file "/root/etcd/ssl/ca-etcd.pem" \
--peer-cert-file "/root/etcd/ssl/cert-etcd.pem" \
--peer-key-file "/root/etcd/ssl/cert-etcd-key.pem" \
--cipher-suites "TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_AES_256_GCM_SHA384"
cd etcd/ssl
etcdctl --endpoints=https://172.31.239.82:12379 --cacert=ca-etcd.pem --cert=cert-etcd.pem --key=cert-etcd-key.pem member list -w table
2.12 - kind 快速搭建k8s测试集群
kind 快速搭建k8s测试集群
sed -i 's/dl-cdn.alpinelinux.org/a.b.com\/artifactory/g' /etc/apk/repositories
docker run -d -e MYSQL_ROOT_PASSWORD=123456 -p 3306:3306 mysql:8.0.31
kind delete cluster -n test-cluster
# v1.25.11 v1.26.6 v1.17.3 v1.28.0
kind create cluster --name test-cluster --image kindest/node:v1.28.0 --config cluster-config.yaml
apiVersion: kind.x-k8s.io/v1alpha4
kind: Cluster
nodes:
- role: control-plane
- role: worker
- role: worker
#cloud-config
passwd:
users:
- name: "core"
ssh_authorized_keys:
- "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCtcjZh2+cPHF19Tz9wMDvvilnA2LIfHi15x8SQQGP2y0mUa40K0AysV4+03AFTbbAjGqT288HWF470aNNE8xGUHWUPN0wNZTsiawrQ96fiypefdLkWBYumbEMZm4KFl2oibm+3nM3aWeJUjBz7BGpaXqOdHhpDPloTYsJxAll/tq86hW8k/91pLJEWxkbUCHoUpPB/uXVoPg4qp1VyuWgPz0/GfLfOJXQx6MDcKFogjLbVqBFq/4bdZ3Saz0XQ5uxlphxhQjS6K3UiUCzwGPd1K0MOM3AQ1vC6cdLCrr18TYNbZXgkTCrX4IR1hSsFnNmd7Wy9GGHYcZi1pICKS9IR jude.x.zhu@newegg.com"
- name: "aaa"
password_hash: "$6$brlNJCkW6ictVVVS$cuFNQVDLA7dU/zyQqOZeyKxoppH8hmQheoCQwnZMUDXVlcKDEJp/E15GJqRCqcZsRYwto3LpSAs1SGNr7K6jn."
ssh_authorized_keys:
- "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCtcjZh2+cPHF19Tz9wMDvvilnA2LIfHi15x8SQQGP2y0mUa40K0AysV4+03AFTbbAjGqT288HWF470aNNE8xGUHWUPN0wNZTsiawrQ96fiypefdLkWBYumbEMZm4KFl2oibm+3nM3aWeJUjBz7BGpaXqOdHhpDPloTYsJxAll/tq86hW8k/91pLJEWxkbUCHoUpPB/uXVoPg4qp1VyuWgPz0/GfLfOJXQx6MDcKFogjLbVqBFq/4bdZ3Saz0XQ5uxlphxhQjS6K3UiUCzwGPd1K0MOM3AQ1vC6cdLCrr18TYNbZXgkTCrX4IR1hSsFnNmd7Wy9GGHYcZi1pICKS9IR jude.x.zhu@newegg.com"
groups:
- "sudo"
- "docker"
networkd:
units:
- name: 00-eno.network
contents: |
[Match]
Name=eno*
[Network]
Bond=bond0
- name: 10-bond0.netdev
contents: |
[NetDev]
Name=bond0
Kind=bond
[Bond]
Mode=active-backup
MIIMonitorSec=1
- name: 20-bond0.network
contents: |
[Match]
Name=bond0
[Network]
DNS=172.16.166.111
DNS=172.16.166.112
Address=172.16.164.133/24
Gateway=172.16.164.1
systemd:
units:
- name: containerd.service
dropins:
- name: 10-use-cgroupfs.conf
contents: |
[Service]
Environment=CONTAINERD_CONFIG=/usr/share/containerd/config-cgroupfs.toml
- name: settimezone.service
enabled: true
contents: |
[Unit]
Description=Set the time zone
[Service]
ExecStart=/usr/bin/timedatectl set-timezone America/Los_Angeles
RemainAfterExit=yes
Type=oneshot
[Install]
WantedBy=multi-user.target
- name: systemd-networkd.service
enable: true
- name: update-engine.service
mask: true
- name: locksmithd.service
mask: true
storage:
filesystems:
- name: "OEM"
mount:
device: "/dev/disk/by-label/OEM"
format: "btrfs"
files:
- filesystem: "OEM"
path: "/grub.cfg"
mode: 0644
append: true
contents:
inline: |
set linux_append="$linux_append systemd.unified_cgroup_hierarchy=0 systemd.legacy_systemd_cgroup_controller"
- path: /etc/flatcar-cgroupv1
mode: 0444
- filesystem: "root"
path: "/etc/hostname"
mode: 0644
contents:
inline: e11k8swk13.mercury.corp
- path: /etc/systemd/timesyncd.conf
filesystem: root
mode: 0644
contents:
inline: |
[Time]
NTP=172.16.72.21 172.16.72.22 172.16.72.23
2.13 - cks
cks证书需要在在cka有效期内考取cks证书
CKS认证考试包括这些一般领域及其在考试中的权重:
- 集群安装:10%
- 集群强化:15%
- 系统强化:15%
- 微服务漏洞最小化:20%
- 供应链安全:20%
- 监控、日志记录和运行时安全:20%
详细内容:
集群安装:10%
- 使用网络安全策略来限制集群级别的访问
- 使用CIS基准检查Kubernetes组件(etcd, kubelet, kubedns, kubeapi)的安全配置
- 正确设置带有安全控制的Ingress对象
- 保护节点元数据和端点
- 最小化GUI元素的使用和访问
- 在部署之前验证平台二进制文件
集群强化:15%
- 限制访问Kubernetes API
- 使用基于角色的访问控制来最小化暴露
- 谨慎使用服务帐户,例如禁用默认设置,减少新创建帐户的权限
- 经常更新Kubernetes
系统强化:15%
- 最小化主机操作系统的大小(减少攻击面)
- 最小化IAM角色
- 最小化对网络的外部访问
- 适当使用内核强化工具,如AppArmor, seccomp
微服务漏洞最小化:20%
- 设置适当的OS级安全域,例如使用PSP, OPA,安全上下文
- 管理Kubernetes机密
- 在多租户环境中使用容器运行时 (例如gvisor, kata容器)
- 使用mTLS实现Pod对Pod加密
供应链安全:20%
- 最小化基本镜像大小
- 保护您的供应链:将允许的注册表列入白名单,对镜像进行签名和验证
- 使用用户工作负载的静态分析(例如kubernetes资源,Docker文件)
- 扫描镜像,找出已知的漏洞
监控、日志记录和运行时安全:20%
- 在主机和容器级别执行系统调用进程和文件活动的行为分析,以检测恶意活动
- 检测物理基础架构,应用程序,网络,数据,用户和工作负载中的威胁
- 检测攻击的所有阶段,无论它发生在哪里,如何扩散
- 对环境中的不良行为者进行深入的分析调查和识别
- 确保容器在运行时不变
- 使用审计日志来监视访问
真题模拟
1. Pod 指定 ServiceAccount
Task 1.在现有namespace qa中创建一个名为 backend-sa 的新 ServiceAccount ,确保此 ServiceAccount 不自动挂载 API 凭据。 2. 使用 /cks/sa/pod1.yaml 中的清单文件来创建一个 Pod 3. 最后,清理 namespace qa 中任何未使用的 ServiceAccount
k create sa -n qa backend-sa
k explain serviceaccount #获取不挂载API的字段
k edit sa backend-sa -n qa # 复制进来,值为 false
# 好像要用上面的sa,先edit pod1.yaml 加上 serviceAccountName: backend-sa
k apply -f /cks/sa/pod1.yaml
k get pod -oyaml -n qa|grep serviceAccont: #查看所有使用的sa
k dekete sa -n qa xxx #清理
2. RBAC - Rolebinding
Context 绑定 Pod 的 ServiceAccount 的 Role授予宽松的权限,完成以下项目减少权限集合: Task: 一个名为 web-pod 的现有 Pod 在 namespace db 中运行,编辑绑定到pod 的 serviceaccount service-account-web 的现有的 Role, 仅允许对 services 类型的资源执行 get 操作,在 namespace db 中创建一个名为 role-2 ,并仅允许对namespace类型的资源执行 delete 操作的新 role。 创建一个名为 role-2-binding 的新 rolebinbing,将创建的 Role 绑定到 Pod 的serviceaccount。 注意: 请勿删除现有 rolebinding 。
k get role -n db
k edit role -n db xxx # 对services执行get操作
k create role role-2 -n db --verb=delete --resource=namespaces
k create rolebinding role-2-binding -n db --role=role-2 --serviceaccount=db:service-account-web
#验证,可以使用 describe 或者 auth can-i
k describe rolebinding role-2-binding -n db
k auth can-i get services -n db --as=system:serviceaccount:db:service-account-web
k auth can-i delete namespaces -n db --as=system:serviceaccount:aba:service-account-web
https://kubernetes.io/zh-cn/docs/reference/access-authn-authz/authorization/
3. 启用 API server 认证
由 kubeadm 创建的cluster 的k8s api 服务器,出于测试目的,临时配置允许未经身份验证和未经授权的访问,授予匿名用户 cluster-admin 权限。
Task: 重新配置 cluster 的 kubernetes api 服务器,以确保只允许经过身份验证和授权的rest请求。 使用授权模式Node,RBAC和准入控制器 NodeRestriction。 删除用户 system:anonymous 的 Clusterrolebinding 来进行清理。
注意: 所有kubectl配置的未授权的访问,必须更改。一旦完成 cluster 的安全加固,kubectl的配置将无法工作,可以使用master节点上的配置文件 /etc/kubernetes/admin.conf,以确保经过身份验证的授权的请求仍然内允许。
# 修改配置文件
--authorization-mode RBAC,Node
--enable-admission-plugins NodeRestriction
k delete clusterRolebinding system:anonymous
https://kubernetes.io/zh-cn/docs/reference/command-line-tools-reference/kube-apiserver/
#切换到master机器上
kubectl get node -owide --kubeconfig=/etc/kubernetes/admin.conf
4. Sysdig & falco
Task : 使用运行时检测工具来检测Pod tomcat 单个容器中频发生成和执行的异常进程。有两种工具可供使用:
- sysdig
- falco
注意: 这些工具只预装在 cluster 的工作节点,不在master 节点。使用工具至少分析 30 秒, 使用过滤器检查生成和执行的进程,将事件写到 /opt/JSR00101/incidents/summary 文件中,其中包含检测的事件。
格式如下: [timestamp],[uid],[processName] 保持工具的原始时间戳格式不变。
注意:确保事件文件存储在集群的工作节点上。
5. 默认网络策略
Context
一个默认拒绝(default-deny)的 NetworkPolicy 可避免在未定义任何其他 NetworkPolicy 的 Namespace 中意外公开pod。
Task:
为所有类型为 Ingress + Egress 的流量在 namespace testing 中创建一个名为 denypolicy 的新默认拒绝 NetworkPolicy。
此新的 NetworkPolicy 必须拒绝 namespace testing 中的所有的 Ingress + Egress 流量。
将新创建的默认拒绝 NetworkPolicy 应用与在 namespace testing 中运行的所有的pod。
# 拒绝所有pod
# https://kubernetes.io/zh-cn/docs/concepts/services-networking/network-policies/#default-deny-all-ingress-and-all-egress-traffic
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: denypolicy
namespace: testing
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
# 应用
kubectl apply -f net.yaml
# 检查
kubectl describe networkpolicy -n testing denypolicy
6. 审计日志 log audit
在 cluster 中启用审计日志。为此,请启用日志后端,并确保:
- 日志存储在/var/log/kubernetes/audit-logs.txt
- 日志文件能保存 10 天
- 最多保留 2 个旧审计日志文件
/etc/kubernetes/logpolicy/sample-policy.yaml 提供了基本策略。它仅指定不记录的内容。 注意:基本策略位于 cluster 的 master 节点上。
编辑和扩展基本策略以记录:
- RequestResponse 级别的 persistentvolumes 更改
- namespace front-apps 中 configmaps 更改的请求体
- Metadata 级别的所有 namespace 中的 Configmap 和 secret 的更改
此外,添加一个全方位的规则以在 Metadata 级别记录所有其他请求。
注意: 不要忘记应用修改后的策略。
https://kubernetes.io/zh-cn/docs/tasks/debug/debug-cluster/audit/#audit-policy
apiVersion: audit.k8s.io/v1
kind: Policy
omitStages:
- ReqyestReceived
rules:
- level: RequestResponse
resources:
- group: ""
resources: ["persistentvolumes"]
- level: Request
resources:
- group: ""
resources: ["configmaps"]
namespaces: ["front-apps"]
- level: Metadata
resources:
- group: ""
resources: ["recrets","configmaps"]
- level: Metadata
omitStages:
- "RequestReceived"
备份 kube-apiserver.yaml 文件,然后修改,新增一下内容:
- --audit-log-path: /var/log/kubernetes/audit-logs.txt
- --audit-log-maxage: 10
- --audit-log-maxbackup: 2
- --audit-policy-file=/etc/kubernetes/logpolicy/sample-policy.yaml
volumeMounts:
- mountPath: /var/log/kubernetes
name: audit-log
readOnly: false
- mountPath: /etc/kubernetes/logpolicy
name: audit
readOnly: true
volumes:
- hostPath:
path: /var/log/kubernetes
type: DirectoryOrCreate
name: audit-log
- hostPath:
path: /etc/kubernetes/logpolicy
type: DirectoryOrCreate
name: audit
重启 kubelet
# 重启
systemctl daemon-reload
systemctl restart kubelet
#检查
tail -f /var/log/kubernetes/audit-log.txt
7. 创建Secret
在 namespace istio-system 中获取名为 db1-test 的现有 secret 的内容。 将 username 字段存储在 /cka/sec/user.txt 文件中,并将 Password 字段存储在名为 /cks/sec/pass.txt 文件中。
注意: 不要再一下步骤中使用/修改先前创建的文件,如果需要,可以创建新的临时文件。
在 istio-system namespace 中创建一个名为 db2-test 的新 secret ,内容如下: username: adf password: KvLft
最后,创建一个新的pod,可以通过卷访问secret db2-test:
- 容器名dev-container
- 镜像 nginx
- 卷名 secret-volume
- 挂载路径 /etc/secret
https://kubernetes.io/zh-cn/docs/concepts/configuration/secret/#restriction-secret-must-exist
k get secret db1-test -n istio-system
mkdir -p /cks/sec
cd /cks/spc
echo 值 |base64 -d > user.txt
echo 值 |base64 -d > pass.txt
cat user.txt
cat pass.txt
k create secret generic db2-test -n istio-system --from-literal=username=adf --from-literal=password=KvLft
搜 secret ,复制模板改要求即可。
8. dockerfile 检测
分析和编辑给定的 Dockerfile /cks/docker/Dockerfile,并修复在文件中拥有的突出的安全/最佳实践问题的两个指令。
分析和编辑给定清单文件 /cks/docker/deployment.yaml ,并修复在文件中突出的安全/最佳实践问题的两个字段。
注意:请勿删除或者添加配置设置;只需修改现有的配置设置,让两个配置不再有安全问题。
注意: 如果需要非特权用户来执行任何项目,请使用用户ID 65535 的用户 nobody。
只需要修改即可,不需要创建。
Dockerfile 看题目,image的tag不正确,然后需要将 USER root 换成 **USER nobody**
Deployment 文件将 SecurityContext 里面的admin权限删掉:**SYS_ADMIN**,第二个是 pod 的 label标签和 matchLabels 不匹配,修改 pod 的 metadata labels。
9. 沙箱运行容器 gVisor
该 cluster 使用 containerd 作为 CRI 运行时,containerd 的默认运行时处理程序是runc。 Containerd 已准备好支持额外的运行时处理程序 runsc(gVisor)
Task:
使用名为 runsc 的现有运行时处理程序,创建一个名为 untrusted 的 RuntimeClass。
更新 namespace server 中的所有pod以在 gVisor 上运行。
可以在 /cks/gVisor/rc.yaml 中找到一个模板清单。
# 创建 runtimeclass,官网搜索模板
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
# 用来引用 RuntimeClass 的名字
# RuntimeClass 是一个集群层面的资源
name: untrusted
# 对应的 CRI 配置的名称
handler: runsc
# 查看pod,是否是修改deploy,添加字段并验证
runtimeClassName: untrusted
10. 容器安全,删除特权pod
最佳实践是将容器设计为无状态和不可变的。
Task:检查在 namespace production 中运行的pod,并删除任何非无状态或者非不可变的pod。
使用以下对无状态和不可变的严格解释:
- 能够在容器内存储数据的 Pod 容器必须被视为非无状态的。
- 被配置为任何形式的特权 Pod 必须被视为可能是非无状态和非不可变的。
思路:
要求删除非无状态和非不可变的pod,即删除任何形式的特权pod和挂载volume的pod。
# 查询是不是pod控制
k get all -n production
# 查询pod
k get pod -n production
# 每个pod查看yaml,如果满足要求直接删除
k get pod -n production -oyaml xxx
k delete pod -n production xxx
11. container 安全上下文
Context
Container Security Context 应在特定 namespace 中修改 Deployment
Task
按照如下要求修改 sec-ns 命名空间中的 Deplyment secdep
- 用 ID 为 30000 的用户启动容器(设置用户ID为 30000)
- 不允许进程获取超出其父进程的特权(禁止 allowPrivilegeEscalation)
- 以只读方式加载容器的根文件系统(对根文件的只读特权)
k create deploy secdep –image=nginx –replicas=2 –dry-run=client -oyaml -n sec-ns
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: secdep
name: secdep
namespace: sec-ns
spec:
securityContext: # 添加
runAsUser: 30000
replicas: 2
selector:
matchLabels:
app: secdep
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: secdep
spec:
containers:
- image: nginx
name: nginx
resources: {}
securityContext: # 添加,如果有多个容器,每个容器都要添加
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
12. 网络策略 NetworkPolicy
Task
创建一个名为 pod-restriction 的 NetworkPolicy 来限制对在 namespace dev-team 中运行的 Pod products-service 的访问。
只允许以下 Pod 连接到 Pod products-service
- namespace qa 中的 Pod
- 位于任何 namespace,带有标签 environment: testing 的 Pod
注意:确保应用 NetworkPolicy。 你可以在/cks/net/po.yaml 找到一个模板清单文件。
思路:
- 查看pod的label
- 使用ingress,查看 ns qa 的label
- 最后apply
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: pod-restriction
namespace: dev-team
spec:
podSelector:
matchLabels:
name: products-service
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
name: qa
- from:
- podSelector:
matchLabels:
environment: testing
namespaceSelector: {}
# apply 和验证
k create -f netpol.yaml
k describe networkpolicy pod-restriction -n dev-team
13. Trivy 扫描镜像安全漏洞
Task 使用 Trivy 开源容器扫描器检测 namespace kamino 中 Pod 使用的具有严重漏洞的镜像。
查找具有 High 或者 Critical 严重性漏洞的镜像,并删除使用这些镜像的 Pod。
注意:Trivy仅安装在cluster的master节点上,在工作节点上不可使用。 必须切换到cluster的master节点才能使用Trivy.
trivy image --help
trivy image --severity HIGH,CRITICAL image:tag
k get pods --namespace kamino --output=custom-columns="Name:.metadata.name,Img:.spec.containers[*].image"
k delete pod -n kamino xxx
14. AppArmor
Context
AppArmor 已在 cluster 的工作节点上被启用,一个 AppArmor 配置文件已存在,但尚未被实施。
Task
在 cluster 的工作节点上,实施位于 /etc/apparmor.d/nginx_apparmor 的现有 AppArmor 配置文件。
编辑位于 /home/candidate/KSSK00401/nginx-deploy.yaml 的现有清单文件以应用 AppArmor 配置文件。最后,应用清单文件并创建其中指定的Pod。
15.
2.14 - 准入控制器
准入控制器
准入控制器 是一段代码,它会在请求通过认证和鉴权之后、对象被持久化之前拦截到达 API 服务器的请求。
准入控制器可以执行**验证(Validating)和变更(Mutating)**操作。变更控制器可以根据被其接受的请求更改相关对象;验证控制器则不行。
准入控制器限制创建、删除、修改对象的请求。不会阻止读取(get watch list)对象的请求。
准入控制阶段
两个阶段。第一阶段,运行变更准入控制器。第二阶段,运行验证准入控制器。
如果两个阶段之一的任何一个控制器拒绝了某请求,则整个请求将立即被拒绝,并向最终用户返回错误。
启用: –enable-admission-plugins=NamespaceLifecycle,LimitRanger …
关闭: –disable-admission-plugins=PodNodeSelector,AlwaysDeny …
2.15 - 容器运行时安全
容器运行时安全
运行时安全是在容器运行时通过检测和防止恶意行为来提供主动保护,整个容器生命周期中的最后一道安全屏障。
其核心思想是监控并限制容器中高危的行为,缩小容器进程的能力和权限。
容器本身是利用了 Namespace 和 Cgroup 技术,将容器和宿主机之间的资源进行隔离和限制。
Namespace 是 Linux 提供的一种内核级别的环境隔离功能,主要用途是对容器提供资源的访问隔离。Cgroup 是限制容器对资源的占有。
虽然这种隔离限制从资源层面实现了对容器和宿主机之间的环境独立,宿主机的资源对容器不可见。但是这种方式并没有达到真正意义上的安全隔离,由于容器的内核和宿主内核共享,一旦容器中通过恶意行为进行一些高危的操作权限,
或者是利用内核漏洞,往往就能突破这种资源上的隔离,造成容器逃逸,重新危害到宿主机及上面运行的其他容器。
目前 Linux 内核提供一系列的安全能力可以对这些攻击行为进行有效防护。结合内核安全技术的能力,这些技术的作用范围可以简单地分为两种:一种限制是限制行为本身,另一种则是限制行为作用的对象范围。
Capabilities 和 Seccomp
在Linux系统中 Root 用户作为超级用户拥有全部的操作权限,以 Root 身份运行容器,相当于将容器资源限制大门的钥匙交给容器本身,这是十分危险的。但是以非 Root 身份在后台运行容器的话,由于缺少权限容器中的应用进程容易处处受限。
为了适用这种复杂的权限需求,Linux 细化了 Root 权限的管控能力,将超级用户的权限分解为细粒度的单元,称为 Capabilities 。例如, CAP_CHOWN 允许用户对文件的 UID 和 GID 进行任意修改,即执行 chown 命令。
几乎所有与超级用户相关的特权都被分解成单独的 Capability,可以分别启用或者禁用。这种权限机制的访问控制,控制容器运行所需的 Capabilities 范围,可以有效切断容器中攻击者的行为操作。即使容器攻击者取得了 Root 权限,由于不能获得主机的完全的操作权限,进一步限制了攻击对宿主机的破坏。
但是基于 Capabilities 的权限访问管理,有时候并不能很好地限制容器的操作系统。例如, SYS_ADMIN 管理了诸多系统调用的访问权限。一旦应用进程因为需要进行 sethostname 这样的操作而在容器中开启了 SYS_ADMIN 组的 Capabilities,那么也就让容器具有了 mount 这类可以挂载系统资源的操作权限,导致容器存在逃逸的风险。
Seccomp (Secure Computing Mode)安全计算模式同样也是一种 Linux 内核提供的安全特性,允许用户使用可配置的策略过滤系统调用,该策略使用 BPF 规则实现,从而使 Seccomp 可以对任意的系统调用及其参数进行过滤。
MAC
Namespace 的隔离机制让宿主机上的资源对容器不可见,但是没有限制容器中进程的访问权限,资源访问权限的权利是由 Linux DAC(Discretionary Access Control,自主访问控制,简称 DAC)机制来完成的,主要依赖进程的 uid 和 gid 进行管理。
一旦容器中的攻击者突破 Namespace 的界限,往往就可以对容器外的资源进行访问。而解决这一安全风险的关键就是强制访问控制(Mandatory Access Control)MAC 。其中最熟知的 MAC 访问控制安全模块是 SELinux、AppArmor等。
DAC通常允许授权用户自主改变客体的访问控制属性,可以指定其他用户是否有权访问该客体。然而,DAC 机制只约束了用户、同用户组内的用户、其他用户对文件的可读、可写、可执行权限,这对系统的保护作用非常有限。
Linux 系统中所有内容都是以文件的形式保存和管理的,即一切皆文件。
为了克服 DAC 这种脆弱性,出现了 MAC 机制,其基本原理是利用配置的安全策略来控制对客体的访问,且这种访问不被单个程序和用户所影响。
SELinux
Security-Enhanced Linux 是由美国国家安全局(NSA)联合其他的安全机构(如SCC公司)共同开发的一套 MAC 安全认证机制。
Selinux 规定了每个对象(程序、文件和进程等)都有一个安全上下文(Security Context),它依附于每个对象身上,包含了许多重要的信息。包括 Selinux 用户、角色、类型和级别等。
管理员可以通过定制安全策略来定义上下文,从而定义哪种对象具有什么权限。当一个对象需要执行某个操作时,系统会按照该对象以及该对象要操作的对象的安全上下文所定制的安全策略来检查相对应的权限。如果全部权限都符合,系统就会允许该操作,否则将阻断这个操作。
SELinux 与 DAC
在启用了 SELinux 的 Linux 操作系统中,SELinux 并不是取代传统的 DAC 机制。当某个对象需要执行某个操作时,需要先通过 DAC 机制的检测,再由 SELinux 定制的安全策略来检测。如果 DAC 规则拒绝访问,则根本无需使用 SELinux 策略。只有通过 DAC 和 SELinux 的双重权限检查确认之后,才能执行操作。
容器与 SELinux
容器在默认配置下是没有开启 SELinux 功能的,需要管理者修改 Docker 守护进程中的参数配置进行开启。
AppArmor
AppArmor 的目的是希望开发一个比 SELinux 更简单易用的访问控制模块。
RedHat 旗下的Linux发行版都预装提供 SELinux 设置,包括 RHEL、 Centos 、Fedora。而Apparmor 安装在 Debian、Ubuntu等发行版上。
与 SELinux 不同,AppArmor 是作为 DAC 机制的补充,用于限制指定目标程序的资源访问权限,例如是否允许读/写某个特定的目录/文件、打开/读/写网络端口以及是否具备某类 Linux Capabilities 等。为了简单易用,Apparmor使用文件名(路径名)作为安全标签,而SELinux使用文件的 inode 作为安全标签。在文件系统中,只有inode才具有唯一性,因此相比于 SELinux,通过改名等方式,AppArmor 存在被绕过的风险。
LSM
不管是 SELinux 还是 AppArmor,其实都是 Linux 安全模块(Linux Security Module)LSM,都是基于 LSM 框架。是一种 Linux 操作系统内核提供的一种安全机制,来完成对进程对 Linux 资源访问权限的判断。LSM是和内核代码一起编译在内核文件中,并且只能在系统启动时就进行初始化。
eBPF 与 LSM 模块
相较于 LSM 框架,eBPF 提供了一种更加简便安全的方式在 Linux 内核中运行自定义的代码。通过编写内核模块来改变或扩展内核行为,往往需要足够的内核编程知识,并且在编写使用过程中需要十分谨慎,以免因为一些疏忽带来内核代码崩溃的问题,甚至留下攻击者可以利用的漏洞。因此为了保障内核安全性,往往内核模块的开发以及内核新版本的发布,都需要长时间的分析测试。
而 eBPF 程序的开发则不需要通过复杂的内核编译,只需要引入相关结构体的头文件申明,这就给 eBPF 程序的开发降低了难度。同时 eBPF 在安全性保证上提供了一道有效的屏障—— eBPF 验证器:在整个 eBPF 的使用过程中,内核会在加载 eBPF 程序时对 eBPF 程序进行分析验证,保证 eBPF 程序不会造成内核崩溃等问题。
更具有优势的一点是,eBPF 程序是可以动态地从内核中加载或删除,而不像 LSM 模块需要重启系统才能进行模块加载,完全可以做到不打断任何已经存在的进程。
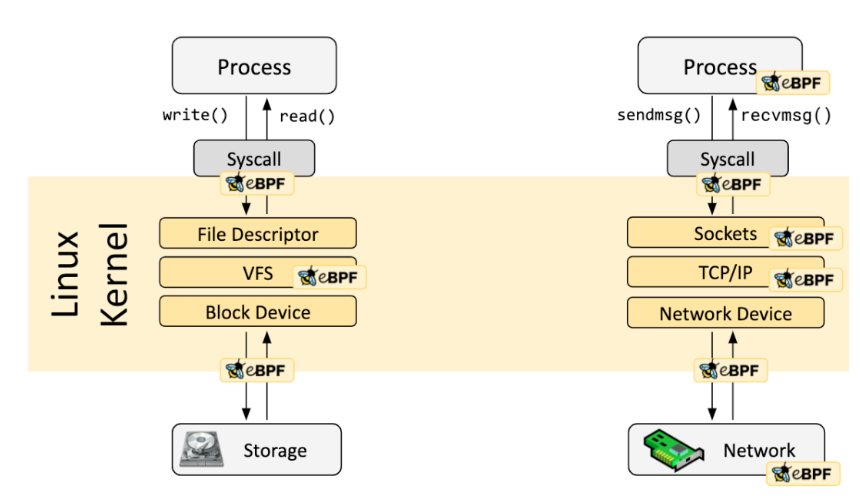
eBPF 与容器安全
eBPF 提供了一种便利的可基于系统或程序事件高效安全执行特定代码的通用能力,并且它可检测的事件覆盖了系统的各个方面(如下图所示),提供了丰富的可观察信息,甚至在 Linux 5.7 版本后 eBPF 程序可以插入 LSM hook 点。
对于容器环境来说,所有运行在一台机器上的容器都和主机共享内核,内核了解主机上运行的所有应用代码。eBPF 的 Hook 点可以说是遍布内核的各个角落,这对于容器安全的检测和防护是很大的助力,方便了对容器中正在进行的操作的分析和判断,近些年来有许多利用这项新技术来解决一些容器安全问题的工具。
当前这类安全上的工具主要可以分为两类:一类是确保网络活动的安全,eBPF 最初就是用于网络数据包过滤的技术,可以在网络驱动中尽可能早的位置提供最优的数据包处理能力,过滤并丢弃恶意或非预期的流量以及防范 DDOS 攻击等。而另一类则是检测恶意行为,确保应用程序在运行时的行为安全。例如利用 eBPF 同样可以在系统调用的入口处插入检测过滤程序,但是相比于 Seccomp 更强大的地方在于,eBPF 程序可以对其中的指针参数进行解引用,这也就方便了更进一步的行为分析。
下表列举了当前比较有名的基于 eBPF 开发的安全工具:
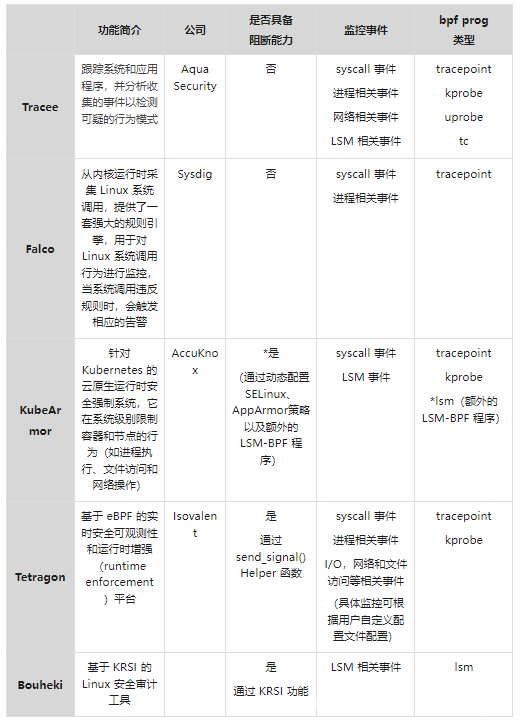
容器运行时安全的未来:
当前云原生的技术大多数被服务于 Web 应用的相关业务,此类业务往往把性能要求放在较为靠前的位置,对于设备上选用的安全加固技术都会有性能方面的考量。而 eBPF 的出现为容器安全带来了一种能够动态、轻量、无感知的提升防御能力的方式。其全面的观测能力,可以轻松地监控到容器安全可观测性的四个黄金信号:进程执行、网络套接字、文件访问和七层网络身份,保证了安全检测的全面性。
在未来的发展过程中,eBPF 的相关应用将是容器运行时安全最重要的助力。同时,不可忽视的是对低版本内核系统上的安全防护,目前并在未来很长的一段时间内,大多数的主机服务器上仍然将运行着 Linux 3.* 以及 4.* 的系统。对于这些系统来说,Seccomp、LSM 模块等内核安全机制依旧是保障容器安全不可或缺的部分。
3 - Linux
Linux
3.1 - Network
Network
Network
SDN(Software Defined Networking)是当前热门技术之一,目前已经普遍得到大家共识。本文整理了SDN实践中的一些基本理论和实践案例心得。
3.1.1 - 基础知识
网络基础概念
网络基础知识
vxlan
全称 Virtual extensible local area network,是用三层协议封装的二层协议,允许第二层数据包在第三层网络上传输。通过 Overlay 技术旨在扩展 vlan, 以解决大型云计算部署中虚拟网络数量不足的问题。
DSR(Direct Server Return)
默认情况下,cilium 的 BPF NodePort 实现以 SNAT 模式运行。也就是说,当节点外部流量到达且节点确定 NodePort 或者 xternallPs 服务的后端位于远程节点时,则 该节点通过执行 SNAT 代表其将请求重定向到远程后端。不需要额外的 MTU 更改,而代价是来自后端的答复。
cilium 下通过将 nodeport.mode 改成 dsr 更改此设置,使 Cilium 的 bpf nodeport实现在 dsr 模式下运行。
DSR 需要在 Native-Routing,不能再任何 tunneling 模式下工作。
XDP
express data path ,能够在网络包进入用户态直接对网络包进行过滤或者处理。XDP 依赖于 ebpf技术。
Encapsulation(封装)
使用基于 UDP 的封装协议 vxlan 形成一个 tunnel。
优点简单,缺点是由于添加了 header,MTU过大低于本地路由。导致特定网络连接的最大吞吐率低,可以通过巨型帧缓解。
3.1.2 - 网络协议
网络协议
tcp: 流量控制 超时重传 拥塞控制
传输层的数据包大小超过 MSS (TCP最大报文段长度),就要将数据分块,这样即使中途有一个分块出问题,只需要重传这个分块,而不用重新发送整个数据包。 在 TCP 协议中,每个分块称为 TCP段。
网络层最常用的是IP协议,将传输层的报文作为数据部分,再加上IP包头组装成IP报文,如果报文大小超过 MTU(以太网中一般为1500字节)就会再次进行分片,得到一个即将发送到网络的IP报文。
IP地址分成的两种意义:
- 一是网络号,负责标识该IP地址是属于哪个【子网】;
- 二是主机号,负责标识同一【子网】下的不同主机;
需要配合子网掩码才能计算出 IP地址的网络号和主机号。 如: 10.100.122.0/24 /24就是 255.255.255.0 子网掩码,二进制有24个1.
- 计算网络号: 将IP与子网掩码做 AND 运算
- 计算主机号: 将子网掩码取反后与IP地址进行与运算
网络接口层: 生成了 IP 头部之后,接下来要交给 网络接口层 在 IP 头部的前面加上 MAC 头部,并封装成数据帧发送到网络上。
可靠传输 TCP
TCP报文头部格式:
- 源端口号 :确认应用
- 目的端口号 :确认目的应用
- 序号 :解决包乱序问题
- 确认序号 :确认发出去对方是否收到,没收到就重新发送,解决丢包问题
- 状态位 :SYN(发起一个连接) ACK(回复) RST(重新连接) FIN(结束连接),带有状态位的包的发送,引起双方状态变更。
- 首部长度 :
- 保留
- 校验
- 窗口大小 : TCP要控制流量,通信双方个声明一个窗口(缓存大小),表示当前处理的能力。还要拥塞控制,控制发送的速度。
- 紧急指针
- 选项
网络包 IP
IP 报文头部:
- 版本
- 首部长度
- 服务类型
- 协议 : http通过tcp传输,填写 06,表示协议为tcp
- 校验
- ttl
- 源 IP 地址 :客户端输出的IP地址
- 目标 IP 地址 : web 服务器 IP
MAC
MAC 头部:
- 接收方 MAC 地址
- 发送方 MAC 地址
- 协议类型 :IP协议和 ARP协议
HTTP1.0 无状态、无连接
HTTP1.1 持久连接 请求管道化 增加缓存处理(新的字段如cache-control) 增加Host字段、支持断点传输等
HTTP2.0 二进制分帧 多路复用(或连接共享) 头部压缩 服务器推送
HTTPS 优化:
tls协议,目的是为了通过非对称加密握手协商或者交换出对称加密密钥。
尽量序言用 ECDHE 密钥交换算法替代 RSA 算法,使用 tls1.3 (简化了握手的步骤,握手只要1RTT)
证书优化
会话复用
SYN seq = clinet_isn
ACK = seq + 1 SEQ = server_isn
ACK = server_isn + 1
三次握手建立连接的主要原因是防止历史连接 初始化了连接。
3.1.3 - 网关协议
网关协议
网关协议
kubernetes 需要安装 CNI 网络插件进行请求通信。遇到的问题如:
- arp 地址不正确,服务请求返回异常
- 开启 bgp 协议
- 网卡的几种模式
- …
路由器工作在 IP 层,其作用是根据 IP 地址将数据包传输到正确的目的地,因此路由器必须知道网络的“地图”才能正确投递,这个”地图“就是存储在路由表中的路由规则,简称路由。
根据获得路由的方式可以分为:
- 静态路由:管理员配置的路由
- 动态路由:路由器通过算法动态学习和调整得到的路由。常说的路由协议就是指 动态路由的学习算法。
根据作用域不同可以分为:
- 内部网关协议(IGP),通常包括 RIP 和 OSPF
- 边界网关协议(BGP)
BGP路由(边界网关协议)
Border Gateway Protocol
当网络过大时,会导致路由表过大而难以维护,这时候采用分治的方法,将一个大网络划分为若干个小网络,这些小网络称为自治系统(AS),BGP就是用于自治系统间的通信。
边界网关协议就像是互联网的邮政服务,当有人把信投进邮筒时,邮政服务会处理邮件,并选择一条高效的路线将信投递给收件人。 同样地,当有人通过互联网提交数据时,BGP负责寻找数据能传播的可用路径,并选择最佳路由,通常在自治系统之间跳跃。
并不是 是不是所有的 AS 之间的通信都需要 BGP ,当只有两 AS 间存在多条路径,需要做路由策略和选择才需要 BGP,如果AS只有一出口或者所有的出口指向一个 ISP 时,是不需要 BGP 的。
基本概念
BGP 允许基于策略的路由选择,策略与多种因素相关,有 AS 的网络管理者确定,人为影响的因素较大。
每个划分后的小网络称为 AS ,每个 AS 都有自己的 AS号码(ASN)。根据类型不同,也被分为不同类型的 AS 。
BGP 是运行在 TCP 协议之上的,BGP 的邻居关系(或称为对等实体 peer)是通过人工配置实现的,对等实体之间通过 TCP 端口 179 创建会话交换数据。 BGP 路由器会周期发送19自己的保持存活(keep-alive)消息维持连接。在各种路由协议中,只有 bgp 使用 TCP 作为传输层协议。
与其他路由协议对比:
BGP 有两种邻居,其中在同一个 AS 内的 BGP 邻居称为 IBGP(Interior BGP),不同 AS 间的邻居称为 EBGP(Exterior BGP),无论是 IBGP 或者 EBGP,上面都运行着 BGP 协议,也就是说与 BGP 路由器直连的内部路由器不一定是它的 IBGP。
注意: BGP 邻居不是自己发现的,而是手动配置的,原因是:
- 可以与对端设备用任何IP地址建立邻居,而不必限于某个固定的接口IP。这样当两台设备采用环回地址而非直连地址建立 BGP 邻居时,即时主链路断了,也可以切回到备份链路上,保持邻居不断。
- 可以跨越多台设备建立邻居。当一个 AS 有多个设备运行 BGP 建立域内全连接时,不必每台设备物理直连,只要用IGP保证建立邻居的地址可达,即可建立全网连接,减少不必要的链路。
路由注入及宣告
BGP路由器的路由注入和通告都是为了修改 BGP 路由表。
当路由器之间建立 BGP 邻居之后,可以相互交换 BGP 路由。一台运行了 BGP 协议的路由器,会将 BGP 得到的路由与普通的路由分开存放,所以 BGP 路由器会同时拥有两张路由表。 普通路由的称为 IGP路由表,用 show ip route 就能看到的路由表。IGP路由表的路由信息只能从 IGP 协议和手工配置获得,并且只能传递给 IGP 协议; 另一张是 BGP路由表,用命令 show ip bgp 查看。
初始状态下,BGP的路由表为空,没有任何路由,要让 BGP 传递相应的路由,只能先将该路由注入BGP路由表,之后才能在BGP邻居之间传递。注入的方式:
- 动态注入
- 半动态路由注入
- 静态路由注入
在注入路由后, BGP 路由器之间会进行通告。通告要遵守以下规则:
- BGP 路由器只把自己使用的路由通告给相邻体
- BGP 路由器从 EBGP 获得的路由会向所有BGP相邻体通告
- 从 IBGP 获得的路由不会向 IBGP 相邻体通告
- 从 IBGP 获得的路由是否通告给 EBGP 相邻体要依 IGP 和 BGP 同步的情况而定。
检查 BGP 的命令:
IGP (内部网关协议)
在 AS 内部的协议,主要包括 RIP协议 和 OSPF协议。
RIP
距离向量协议,UDP协议,端口号为 520。
工作过程:
- RIP 路由器中初始的路由表只有自己的直连路由;路由表中每一项为一个三元组,即目标网络,该条路由信息的下一条地址以及距离;距离定义为经过的路由器数。
- 每个路由器发起自己的更新周期,将自己的路由表信息发送给相邻的路由表,接受到该路由表信息的临接路由表更新自己的路由表信息;
- 存在路由环路问题
OSPF(Open Shortest Path First)
使用的是链路状态路由算法,直接使用IP协议,协议类型为89.
3.1.4 - 操作网络命令
操作网络命令
Linux 下控制网络的命令:
- curl & wget
- ping
- tracepath & traceroute
- mtr
- host
- whois
- ifplugstatus 是否有网线插入网络设备接口, sudo apt-get install ifplugd
- ifconfig
- ifdown & ifup 启用或者禁用设备
- dhclient
- netstat
route 命令
route 命令用于显示和操作 IP路由表。
要实现两个不同的子网之间的通信,需要一台连接两个网络的路由器,或者同时位于两个网络的网关来实现。
在Linux系统中,设置路由通常是为了解决以下问题: Linux机器在局域网中,局域网有一个网关,能够让机器访问 Internet ,那么需要将这台机器的IP地址设置为Linux机器的默认路由。 直接执行route命令来添加路由,不会永久保存。当网卡重启或者机器重启之后,该路由会失效;可以在 /etc/rc.local 中添加 route 命令来保证该路由设置永久有效。
命令参数:
-c 显示更多信息
-n 不解析名字
-v 显示详细的处理信息
-F 显示发送信息
-C 显示路由缓存
-f 清除所有网关入口的路由表
-p 与 add 命令一起使用时使路由具有永久性
add:添加一条路由
del:删除一条路由
-net:目标地址是一个网络
-host:目标地址是一个主机
netmask:当添加一个网络路由时,需要使用网络掩码
gw:路由数据包通过网关。注意,指定的网关必须能够达到。
metric:设置路由跳数
Command 指定想运行的命令 (Add/Change/Delete/Print)
Destination 该路由的网络目标
mask Netmask 指定与网络目标的网络掩码(子网掩码)
Gateway 指定网络目标定义的地址集和子网掩码可以到达的前进或者下一跳跃点 IP 地址
metric Metric为路由指定一个整数成本值,当在路由表的多个路由中进行选择时可以使用
实例1
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.25.64.1 0.0.0.0 UG 0 0 0 eth0
172.25.64.0 0.0.0.0 255.255.240.0 U 0 0 0 eth0
第二行表示主机所在网络的地址为 172.25.64.0,若数据传送目标是在本局域网内通信,则可以直接通过 eth0 转发数据包; 第一行表示传送的目标是访问 Internet,则由接口 eth0 将数据包发送到网关 172.25.64.1。
其中 Flags 标志说明:
- U Up表示此路由当前为启动状态
- H Host表示此网关为一个主机
- G Gateway 表示网关是一个路由器
- R Reinstate Route,使用动态路由重新初始化的路由
- D Dynamically 此路由是动态性地写入
- M Modified 此路由是由路由守护程序或者导向器动态修改
- ! 表示此路由当前为关闭状态
路由工作原理
路由:数据从源主机到目标主机的转发过程(路径)。
路由器和交换机的区别:
- 数据在同一网段的转发用交换机。
- 数据在不同网段的转发用路由器。
路由器:能够将数据包转移到正确目的地,并在转交过程中选择最佳路径的设备。
原理
根据路由表查找接口进行数据转发,相邻的路由器接收到数据包并且查看数据包的目标地址,再转发到网络接口和对应的主机。
路由表的形成
路由表是路由器中维护的路由条目的集合,路由器根据路由表做路径选择。 路由表中有直连网段和非直连网段两种。
直连网段:路由器上配置了接口的 IP 地址,并且状态是 Up 状态,由此产生直连路由。 非直连网段:没有跟路由器直接连接的网段,就是非直连网段。
对于非直连网段,需要静态路由和动态路由,将网段添加到路由表中。
静态路由和默认路由
- 静态路由:由管理员手工配置,优点在于稳定且可以对路由的行为进行控制,是单向的,缺乏灵活性。
- 默认路由:当路由器在路由表中找不到目标网络的路由条目时,路由器把请求转发到默认路由接口。
当路由表中存在静态路由和默认路由的时候,静态路由优先级最高,匹配上了会立刻转发;如果没有匹配上静态路由,则按照默认路由进行转发。
命令行查看路由表
route -n
netstat -rn
ip route show dev <interface>
设置网络接口
ifconfig
netmask
#eg
ifconfig eth0 192.168.1.100 netmask 255.255.255.0
ifconfig 命令已经被新的 ip 命令所替代,建议在新的系统中使用 ip 命令来管理网络接口。
#新增一个IP地址
ip addr add 192.168.1.100/24 dev eth0
#查询
ip addr show eth0
#删除
ip addr del 192.168.1.100/24 dev eth0
3.1.5 - docker 四种网络模型
- bridge: 使用 –network bridge 指定,默认使用 docker0 ;
- host: 使用 –network host 指定;
- none: 使用 –network none 指定;
- container:使用 –network container:(name/id)指定。
Docker 四种网络模型:
1. bridge 模式
Docker的默认网络设置,此模式会为每一个容器分配 Network Namespace,设置ip等,并将一个主机上的 Docker 容器连接到一个虚拟网桥上(docker0)上。
2. host 模式
启动容器时使用host模式,就不会获取一个独立的network Namespace,而是和宿主机公用一个 Network Namespace。 容器将不会虚拟出自己的网络,配置IP等,都是使用宿主机的IP和端口。
3. none 模式
在 none 模式下,Docker容器拥有自己的 Network Namespace,但是,并不为docker容器进行任何网络配置。 也就是说这个docker容器没有网卡、IP、路由等信息。
4. container
这个模式是新创建的容器和已存在的容器共享一个 Network Namespace,而不是和宿主机共享。 新创建的容器不会创建自己相关的网卡,而是和指定的容器共享Ip,端口范围等。 同样,除了网络方面。在文件系统,进程列表等方面还是资源隔离的。
常用命令
docker network -h
docker network create my-bridge -d bridge --subnet=172.21.0.0/16
docker run -d --net my-bridge --name nginx nginx
3.1.6 - dns
DNS(Domain Name System,域名系统)是因特网的一项服务,它用于将域名转换为IP地址,而域名又由各级域名服务器进行解析。
常见的DNS记录类型:
1. A记录(Address Record)
A记录用于将域名指向一个IPv4地址。每个域名可以有多个A记录,以支持负载均衡和冗余。
2. CNAME记录(Canonical Name Record)
将一个域名别名映射到另一个域名。允许多个域名指向同一个IP地址或者主机名,通常用于子域名的重定向。
3. MX记录(Mail Exchange Record)
MX记录用于指定邮件服务器的域名。MX记录包含邮件服务器的优先级。
4. NS记录(Name Server Record)
指定负责解析该域名的域名服务器。NS记录通常在域名注册商处设置。
5. CAA记录(Certification Authority Authorization Record)
CAA记录用于限制CA颁发证书的域名。指定哪些证书颁发机构(CAs)被授权为该域名颁发 SSL/TLS 证书。通过CAA记录可以防止中间人攻击和其他安全漏洞。
6. TXT记录(Text Record)
TXT记录用于存储文本信息。TXT记录可以包含任意的ASCII或UTF-8编码的文本。可以用于多用用途,如域验证、SPF记录(反垃圾邮件)、DMARC记录(邮件认证、报告和一致性)、DKIM记录(安全)等。
7. PTR记录(Pointer Record)
PTR记录用于将IP地址转换为域名。PTR记录通常由DNS服务器自动生成。
8. SOA记录(Start of Authority Record)
包含DNS区域的管理信息,如区域的原始名称服务器、区域管理员的电子邮件地址、区域的过期时间等。
9. AAAA记录(IPv6 Address Record)
用于将域名指向一个IPv6地址。每个域名可以有多个AAAA记录,以支持IPv6地址。
10. SRV记录(Service Record)
SRV记录用于指定特定服务的服务器。SRV记录包含服务的名称、协议、端口号、优先级和权重。
11. SPF记录(Sender Policy Framework Record)
SPF记录用于指定哪些邮件服务器可以发送邮件。SPF记录通常由域名注册商设置。
3.2 - 内核
内核算是一个程序员的基本功,更好的理解底层技术。在处理问题时,可以挖掘到问题本质,而不只是停留在技术表面。 特别是在容器领域设计到 cgroups / namespace / unionfs 等基础技术,需要更加深入学习、掌握。
内核是操作系统的核心,其主要功能有:
- 响应中断,执行中断服务程序
- 管理多个进程,调度和分享处理器时间
- 管理进程地址空间和内存管理
- 网络和进程间通信等系统服务程序
内核的活动范围:
- 运行于用户空间,习性用户进程
- 运行于内核空间,处理进程上下文,代表某个特定进程的执行
- 运行于内核空间,处理中断上下文,与进程无关,处理某个特定的中断
本系列围绕在 “进程管理”,“内存管理”,“IO栈”,“网络栈”四大脉络,总结 Linux Kernel 的一些常识知识。
Kernel 版本
Linux内核根据版本具有不同的支持级别,长期支持版本(LTS),超长期支持(SLTS)。

# 查询内核版本
$ uname -a
Linux xxx 5.10.16.3-microsoft-standard-WSL2 #1 SMP Fri Apr 2 22:23:49 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
$ uname -a
Linux xxx 5.4.0-105-generic #119-Ubuntu SMP Mon Mar 7 18:49:24 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
$ uname -a
Linux xxx 5.15.81-flatcar #1 SMP Tue Dec 6 22:42:27 -00 2022 x86_64 Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz GenuineIntel GNU/Linux
# 查询系统版本
$ cat /etc/issue
Ubuntu 20.04.4 LTS \n \l
内核版本说明:
- 前三组数字为:主版本号 + 次版本号 + 修订版本号。
- SMP : 对称多处理机,表示内核支持多核、多处理器。
- x86_64 : 采用64位的cpu
抽象级别和层次
最底层是硬件系统,包括cpu和ram,此外硬盘和网络接口也是硬件系统的一部分。
硬件系统之上是内核,是操作系统的核心。内核是运行在内存中的软件,向cpu发送指令。内核管理硬件系统,是硬件系统和应用程序之间进行通信的接口。
进程是计算机中运行的程序,由内核统一管理,组成了最顶层,称为 用户空间。

内核和用户进程之间最主要的区别是:内核在内核模式下运行,而用户进程是在用户模式中运行。在内核模式中运行的代码可以不受限的访问cpu和内存,这种模式功能强大,因为内核进程可以让整个系统崩溃。只有内核可以访问的空间称为内核空间。
3.2.1 - 修改内核参数
查看、修改 Linux 内核参数
查看、修改 Linux 内核参数
查看
方法一:
通过 /proc/sys 目录,使用 cat 命令查看对应文件的内容。
此目录是 Linux 内核启动后生成的伪目录,其目录下的 net 文件夹中存放了当前系统中生效的所有内核参数、目录树结构与参数的完整名称相关。
如 net.ipv4.tcp_tw_recycle ,对应的文件就是 /proc/sys/net/ipv4/tcp_tw_recycle,文件的内容就是参数值。
执行如下命令查看:
cat /proc/sys/net/ipv4/tcp_tw_recycle
方法二:
通过 /etc/sysctl.conf 文件进行查看,执行以下命令,查看当前系统中生效的所有参数。
sysctl -a
修改
- 方法一:通过修改 /proc/sys 目录中对应的文件,临时修改,重启后会重置为原参数值,一般用于临时性验证。
- 方法二:通过修改 /etc/sysctl.conf 文件进行修改,该方法修改的参数值,永久生效。
- 修改执行的参数值: sysctl -w kernel.domainname=“example.com”
- 修改配置文件: vim /etc/sysctl.conf
- 配置生效: sysctl -p
3.2.2 - 内存管理
内存管理
内核所管理的另一个重要资源是内存。为了提高效率,由硬件管理虚拟内存,内存是按照所谓的 内存页 方式进行管理的。 Linux 包括了管理可用内存的方式,以及物理和虚拟映射所使用的硬件机制。不过内存管理要管理的不止 4KB 缓冲区。
内核不仅管理服务器上的可用物理内存,还可以创建和管理虚拟内存。 内核通过硬盘上的存储空间来实现虚拟内存,这块区域称为 交换空间(swap space)。内核不断在交换空间和实际的物理内存之间反复交换虚拟内存中的内容。
Linux提供了对 4KB 缓冲区的抽象,如slab分配器。这种内存管理模式使用 4KB 缓冲器为基数,然后从中分配结构,并跟踪内存页使用情况, 比如哪些内存页是满的,哪些页面没有完全使用,哪些页面为空。
3.2.3 - 虚拟内存
虚拟内存
虚拟内存
做单片机的时候,程序需要烧录进芯片,这样程序才能跑起来。单片机的CPU是直接操作内存的【物理地址】。
这种情况下,在内存中想同时运行两个程序是不可能的,第二个程序在相同的位置会擦掉第一个程序的所有内容,程序会崩溃。
操作系统时如何解决这个问题的?
这里关键的问题是两个程序都引用了绝对的物理地址,这个正是我们需要避免的。
我们把进程所使用的的地址隔离起来,让操作系统为每个进程分配独立的一套【虚拟地址】,至于虚拟地址最终怎么样落到物理内存里,对进程来说是透明的。
操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。
如果程序要访问虚拟地址的时候,由操作系统进行转换成不同的物理地址,这样不同的进程运行写入不同的物理地址,就不会冲突。
- 我们程序所使用的内存地址叫做虚拟内存地址。
- 实际存在硬件里面的空间地址叫做物理内存地址。
进程持有的虚拟地址会通过 CPU 芯片中的内存管理单元(MMU)的映射关系,来转换成物理地址,然后通过物理地址访问内存。
内核通过硬盘上的存储空间来实现虚拟内存,这块区域称为 交换空间(swap space)。内核不断在交换空间和时间的物理内存之间反复交换虚拟内存中的内容。
操作系统是如何管理虚拟地址和物理地址之间的关系?
主要有两种方式,分别的内存分段和内存分页。
内存分段
程序是由若干个逻辑分段组成的,可由代码分段、数据分段、栈段、堆段组成。 不同的段有不同的属性,所以就用分段(Segmentation)的形式把这些段分离出来。
分段的办法解决了程序不需要关心物理内存地址的问题,但是也有一些缺点:
- 内存碎片问题
- 内存交换的效率低的问题
内存分页
分段的好处是能产生连续的内存空间,但是会出现 外部内存碎片 和 内存交换的空间太大 的问题。 要解决这些问题,就要想出能少出现内存碎片的办法。另外,当需要进行内存交换的时候,让需要交换写入或者从磁盘装载的数据少一点,这样就可以解决,也就是内存分页(Paging)。
分页是把整个虚拟和物理内存空间切成一段固定尺寸的大小,这样一个连续并且固定的内存空间,我们叫做 页。在 Linux 下,每页大小为 4KB 。
虚拟地址和物理地址之间通过 页表 来映射。
页表存储在内存里,内存管理单元(MMU)就将虚拟内存地址转换成物理地址的工作。
当进程访问的虚拟地址在页表中查不到时,系统会产生一个 缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
分页是怎么样解决分段的【外部内存碎片和内存效率低】的问题?
内存分页由于内存空间都是预先划分好的,也就不会像内存分段一样产生间隙非常小的内存。采用分页,页和页之间是紧密排列的,所以不会有外部碎片。
但是,因为内存分页之间分配的最下单位是一页,所以会出现内存浪费,所以针对 内存分页机制会有 内部内存碎片 的现象。
如果内存空间不够,操作系统会把其他正在运行的进程中[最近没有被用]的内存页释放掉,也就是暂时写在硬盘上,称为 换出(Swap Out)。一旦需要的时候,再加载进来,称为 换入**(Swap In)**。所以一次性写入磁盘的只有少数页,不会花太多时间,内存交换的效率就相对比较高。
分页会产生的页表过大问题,有了多级页表,解决空间上问题,但是这会导致CPU在寻址的过程中,需要有很多层表参加,加大了时间的开销。 根据程序的局部性原理,在CPU芯片中加入了 TLB,负责缓存最近常被访问的页表项,大大提高了地址的转换速度。
3.3 - 操作系统
操作系统
操作系统
3.3.1 - Alpine
Alpine
Alpine 操作系统是一个面向安全的轻型Linux发行版。相比其他操作系统,体积非常小。提供自己的包管理工具 apk,可以直接安装各种软件。
Alpine Docker 镜像也继承了 Alpine Linux 发行版的优势,体积只有5M左右。作为基础镜像,有许多好处,如下载快,镜像安全性高,占用更少磁盘等。
apk 包管理
首先替换默认的安装源,采用国内一些源:
- 中科大:http://mirrors.ustc.edu.cn/alpine/
- 阿里云:https://mirrors.aliyun.com/alpine/
- 清华大学:https://mirror.tuna.tsinghua.edu.cn/alpine/
使用方法:
sed -i 's/dl-cdn.alpinelinux.org/mirror.tuna.tsinghua.edu.cn/g' /etc/apk/repositories
apk update # 更新索引生效
apk upgrade --no-cache # 安装可用的升级
Alpine中软件安装包名字可能回合其他发行版不同,可以在 alpine-package 网站搜索。
包管理命令:
查找包:
apk search # 查找所有可用包
apk search -v # 带描述
安装包:
apk add openssh # 安装
apk add openssh vim # 安装多个
apk add --no-cache vim # 不使用本地镜像源缓存,相当于先执行 update ,再执行add
安装信息:
apk info # 已安装的包
apk info -a vim # 显示完整的软件包信息
更新包:
apk upgrade # 升级所有软件
apk upgrade openssh # 指定升级
apk upgrade openssh vim # 指定升级多个
删除包:
apk del vim # 删除
服务管理
alpine 没有使用 systemctl 进行服务管理,使用 rc 系列命令。
精简版的 alpine 没有rc系列命令,可以使用 apk add –no-cache openrc 安装
- rc-update 增加或者删除服务
- rc-status 状态管理
- rc-service 管理服务的状态
- openrc 管理不同的运行级
rc-status -a # 列出所有服务
rc-udate add docker boot # 增加服务到系统启动时运行
rc-service networking restart # 重启网络服务
docker-alpine 镜像
大部分官方镜像都支持使用 Alpine 作为基础镜像。
制作镜像
FROM alpine:3
RUN sed -i 's/dl-cdn.alpinelinux.org/mirror.tuna.tsinghua.edu.cn/g' /etc/apk/repositories
RUN apk update \
&& apk upgrade --no-cache \
&& apk add --no-cache vim
相关资源
- Alpine 官网:https://www.alpinelinux.org/
- Alpine 官方仓库:https://github.com/alpinelinux
- Alpine 官方镜像:https://hub.docker.com/_/alpine/
- Alpine 官方镜像仓库:https://github.com/gliderlabs/docker-alpine
3.3.2 - Flatcar Container Linux
Flatcar Container Linux
Flatcar 是一种容器优化的操作系统,提供了一个最小的操作系统镜像,其中仅包含运行容器所需要的工具。操作系统通过不可变的文件系统交付,并包括自动院子更新。
安装
支持大多数的云供应商、虚拟化平台和裸机服务器上运行。这里主要介绍几种不同的方式在裸机安装:
- 从 ISO 镜像安装
- 使用 PXE 引导
- 使用 iPXE 启动
- 使用 flatcar-install 安装
iPXE
iPXE 是一个开源网络启动固件。提供了一个完整的 PXE 实施,增强了其他功能,例如:
- 通过 HTTP 从 web 服务器启动
- 从无线网络启动
- 从广域网启动
- 从 Infiniband 网络启动
- 使用脚本控制启动过程
- …
iPXE 同时支持 UEFI 和 BIOS 平台。
PXE
PXE 是 Perboot eXecution Environment 的缩写,意为“预启动执行环境”,这种机制可以使计算机通过网络来引导。现在的绝大多数电脑都可以设置通过 PXE 启动。 PXE 的工作原理是 PXE Client 通过 DHCP 获取 IP,并由 DHCP 服务器告诉客户端启动文件的位置,再通过 TFTP 协议传输引导文件,最终引导电脑启动。
使用 flatcar-install 安装
使用 flatcar-install 脚本安装.
fatcar-install -d /dev/sda -i ignition.json
ignition.json 文件包括从 Butane Config 生成的用户信息,否则无法登陆 Flatcar 实例。 如果是在 VMware 上安装,传递 -o vmware_raw 以安装特定于 VMware 的镜像。
flatcar-install -d /dev/sda -i ignition.json -o vmware_raw
选择 channel
Flatcar Container Linux根据每个频道的不同时间表自动更新,可以禁用此功能。生产环境使用 stable channel,要确保使用稳定版本,使用以下选项:
flatca-install -d /dev/sda -C stable
Butane Configs
默认情况下,没有密码和其他方式登陆到新的 Flatcar Container Linux 系统,配置账户、添加 systemd 单元等最简单的方法是通过 Butane Configs。 使用 Butane 生成 Ignition 配置后,安装脚本将处理 ignition.json 文件。
为用户指定ssh密钥core的yaml文件如下:
variant: flatcar
version: 1.0.0
passwd:
users:
- name: core
ssh_authorized_keys:
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDGdByTgSVHq.......
将其转译为 json 文件:
cat c1.yaml |docker run --rm -i quay.io/coreos/butane:latest > ignition.json
sudo ifconfig eno1 172.xxx.xxx.xxx netmask 255.255.255.0
sudo route add default gw 172.xxx.xxx.1
#... 添加 config.json 文件
sudo -E flatcar-install -C stable -d /dev/sda -i config.json
passwd:
users:
- name: "core"
ssh_authorized_keys:
- "ssh-rsa AAAA
- name: "aaa"
password_hash: "$6$brlNJCk"
ssh_authorized_keys:
- "ssh-rsa AAAAB3NzaC1yc2E"
groups:
- "sudo"
- "docker"
networkd:
units:
- name: 00-eno.network
contents: |
[Match]
Name=eno*
[Network]
Bond=bond0
- name: 10-bond0.netdev
contents: |
[NetDev]
Name=bond0
Kind=bond
[Bond]
Mode=active-backup
MIIMonitorSec=1
- name: 20-bond0.network
contents: |
[Match]
Name=bond0
[Network]
DNS=172.xxx
DNS=172.xxx
Address=172.xxx/24
Gateway=172.16.164.1
systemd:
units:
- name: containerd.service
dropins:
- name: 10-use-cgroupfs.conf
contents: |
[Service]
Environment=CONTAINERD_CONFIG=/usr/share/containerd/config-cgroupfs.toml
- name: settimezone.service
enabled: true
contents: |
[Unit]
Description=Set the time zone
[Service]
ExecStart=/usr/bin/timedatectl set-timezone America/Los_Angeles
RemainAfterExit=yes
Type=oneshot
[Install]
WantedBy=multi-user.target
- name: systemd-networkd.service
enable: true
- name: update-engine.service
mask: true
- name: locksmithd.service
mask: true
storage:
filesystems:
- name: "OEM"
mount:
device: "/dev/disk/by-label/OEM"
format: "btrfs"
files:
- filesystem: "OEM"
path: "/grub.cfg"
mode: 0644
append: true
contents:
inline: |
set linux_append="$linux_append systemd.unified_cgroup_hierarchy=0 systemd.legacy_systemd_cgroup_controller"
- path: /etc/flatcar-cgroupv1
mode: 0444
- filesystem: "root"
path: "/etc/hostname"
mode: 0644
contents:
inline: nodeIp
- path: /etc/systemd/timesyncd.conf
filesystem: root
mode: 0644
contents:
inline: |
[Time]
NTP=xxx
3.4 - 虚拟化
虚拟化
虚拟化
3.4.1 - Namespace
Namespace
目前的容器技术、虚拟化技术都能做到资源层面的隔离和限制。
对于容器技术而言,实现资源层面上的限制和隔离,依赖于 Linux 内核所提供的 cgroup 和 namespace 技术。
- cgroup的主要作用:管理资源的分配、限制。
- namespace的主要作用:封装抽象,限制,隔离,使命名空间内的进程看起来拥有全局资源。
Namespace 是什么?
Namespace 是 Linux 内核的一项特性,可以对内核资源进行分区,使一组进程可以看到一组资源;而另一组进程可以看到另一组不同的资源。 该功能的原理时一组资源和进程使用相同的 namespace ,但是这些 namespace 实际上引用的是不同的资源。
Linux 默认提供了多种 namespace,用于对多种不同资源进行隔离。
在之前,单独使用 namespace 的场景比较有限,但是 namespace 却是容器化技术的基石。
发展历程
Namespace 开始进入 Linux Kernel 的版本是 2.4.x,才开始实现每个进程的 namespace。 Linux 3.8 中完全实现了 User Namespace 的相关功能集成到内核。这样 Docker 以及其他容器技术所使用的到的 namespace 相关功能就基本实现了。
Namespace 类型
- Cgroup - CLONE_NEWCGROUP 控制 Cgroup root directory cgroup 根目录。
- IPC - CLONE_NEWIPC 控制 System V IPC POSIX message qucucs 信号量,消息队列
- Nework - CLONE_NEWNET 控制 Network devics , stacks ,ports ,etc 网络设备,协议栈,端口等
- Mount - CLONE_NEWNS 控制 Mount points 挂载点
- PID - CLONE_NEWPID 控制 Process IDs 进程号
- Time - CLONE_NEWTIME 控制时钟
- User - CLONE_NEWUSER 用户和组ID
- UTS - CLONE_NEWUTS 系统主机名和NIS主机名(也称域名)
1. Cgroup namespaces
Cgroup namespace 是进程的 cgroups 的虚拟化视图,通过 /proc/[pid]/cgroup 和 /proc/[pid]/mountinfo 展示。
az6c@WXMIS037:/proc/6184$ ps -ef|grep nginx
root 6184 6163 0 10:20 ? 00:00:00 nginx: master process nginx -g daemon off;
...
az6c@WXMIS037:/proc/6184$ cat cgroup
13:rdma:/
12:pids:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
11:hugetlb:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
10:net_prio:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
9:perf_event:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
8:net_cls:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
7:freezer:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
6:devices:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
5:memory:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
4:blkio:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
3:cpuacct:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
2:cpu:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
1:cpuset:/docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd
0::/
az6c@WXMIS037:/proc/6184$ cat mountinfo
157 114 0:50 / / rw,relatime master:3 - overlay overlay rw,lowerdir=/var/lib/docker/overlay2/l/VVZTUGALNCARSF7HMUB445JPUY:/var/lib/docker/overlay2/l/G3PPKI2BXA3PKTPL7VURBQVVKD:/var/lib/docker/overlay2/l/7NVHGK2ITPX2UT2YGDAJFJE2QD:/var/lib/docker/overlay2/l/GZGJV5VQ4T2ZGCCMGFKXOESBQP:/var/lib/docker/overlay2/l/PRL3DYKGN4DW6BAEZZ3B2YMPMZ:/var/lib/docker/overlay2/l/JT7YW37MP5DRFGKGMD3STR64HG:/var/lib/docker/overlay2/l/VVD7Z66THINOLXHB3V3UHUT5K7,upperdir=/var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a/diff,workdir=/var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a/work
158 157 0:53 / /proc rw,nosuid,nodev,noexec,relatime - proc proc rw
159 157 0:54 / /dev rw,nosuid - tmpfs tmpfs rw,size=65536k,mode=755
160 159 0:55 / /dev/pts rw,nosuid,noexec,relatime - devpts devpts rw,gid=5,mode=620,ptmxmode=666
161 157 0:56 / /sys ro,nosuid,nodev,noexec,relatime - sysfs sysfs ro
162 161 0:57 / /sys/fs/cgroup rw,nosuid,nodev,noexec,relatime - tmpfs tmpfs rw,mode=755
163 162 0:33 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/cpuset ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,cpuset
164 162 0:34 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/cpu ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,cpu
165 162 0:35 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/cpuacct ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,cpuacct
166 162 0:36 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/blkio ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,blkio
167 162 0:37 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/memory ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,memory
168 162 0:38 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/devices ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,devices
169 162 0:39 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/freezer ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,freezer
170 162 0:40 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/net_cls ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,net_cls
171 162 0:41 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/perf_event ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,perf_event
172 162 0:42 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/net_prio ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,net_prio
173 162 0:43 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/hugetlb ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,hugetlb
174 162 0:44 /docker/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd /sys/fs/cgroup/pids ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,pids
175 162 0:45 / /sys/fs/cgroup/rdma ro,nosuid,nodev,noexec,relatime - cgroup cgroup rw,rdma
176 159 0:52 / /dev/mqueue rw,nosuid,nodev,noexec,relatime - mqueue mqueue rw
177 159 0:58 / /dev/shm rw,nosuid,nodev,noexec,relatime - tmpfs shm rw,size=65536k
178 157 8:16 /var/lib/docker/containers/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd/resolv.conf /etc/resolv.conf rw,relatime - ext4 /dev/sdb rw,discard,errors=remount-ro,data=ordered
179 157 8:16 /var/lib/docker/containers/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd/hostname /etc/hostname rw,relatime - ext4 /dev/sdb rw,discard,errors=remount-ro,data=ordered
180 157 8:16 /var/lib/docker/containers/828161c00ee69e3c037a090b8b9d295eea22fe5e81b1a18c85962c5477edd7fd/hosts /etc/hosts rw,relatime - ext4 /dev/sdb rw,discard,errors=remount-ro,data=ordered
121 158 0:53 /bus /proc/bus ro,nosuid,nodev,noexec,relatime - proc proc rw
122 158 0:53 /fs /proc/fs ro,nosuid,nodev,noexec,relatime - proc proc rw
123 158 0:53 /irq /proc/irq ro,nosuid,nodev,noexec,relatime - proc proc rw
124 158 0:53 /sys /proc/sys ro,nosuid,nodev,noexec,relatime - proc proc rw
125 158 0:59 / /proc/acpi ro,relatime - tmpfs tmpfs ro
126 158 0:54 /null /proc/kcore rw,nosuid - tmpfs tmpfs rw,size=65536k,mode=755
127 158 0:54 /null /proc/keys rw,nosuid - tmpfs tmpfs rw,size=65536k,mode=755
128 158 0:54 /null /proc/timer_list rw,nosuid - tmpfs tmpfs rw,size=65536k,mode=755
129 158 0:54 /null /proc/sched_debug rw,nosuid - tmpfs tmpfs rw,size=65536k,mode=755
130 161 0:60 / /sys/firmware ro,relatime - tmpfs tmpfs ro
cgroup namespce 提供一系列的隔离支持:
- 防止信息泄漏(容器不应该看到容器外的任何信息)
- 简化容器迁移
- 限制容器进程资源,因为会把 cgroup 文件系统进行挂载,使得容器进程无法获取上层的访问权限。
Namespace 的主要 API
clone(2)
系统调用 clone(2) 创建一个新的进程,根据参数中的 CLONE_NEW* 设置,逐个对实现对应的配置功能。当然这个系统调用也实现了一些与 namespace 无关的功能。
unshare(2)
系统调用 unshare(2)将进程分配至新的 namespace ,同样,也会根据参数中的 CLONE_NEW* 设置调整实现对应的配置功能。
setns(2)
将进程移动到某一存在的 namespace,这会导致 /proc/[pid]/ns 对应的目录中内容的变更。 进程创建的子进程可以通过调用 unshare(2) 和 setns(2) 来调整所属的 namespace。
3.5 - Systemd
Systemd 是一系列工具的集合,其作用也远远不仅四启动操作系统,还接管了后台服务、结束、状态查询,以及日志归档、设备管理、段元管理、定时任务等许多职责,并支持通过特定事件和特定端口数据触发的任务。
Systemd 是一系列工具的集合,包括了一个专用的系统日志管理服务:Journald。这个服务的初衷是克服 syslog 服务的日志内容容易伪造和日志格式不统一等缺点。 Journald 使用二进制格式报错所有的日志信息,因此日志信息很难被伪造。提供 journalctl 命令来查看日志信息。
Unit 文件
Systemd 可以管理所有的系统资源,不同的资源统称为 Unit(单位)。
Unit文件统一了过去不同系统资源配置格式,例如服务的启/停、定时任务、设备自动挂载、网络配置、虚拟内存配置等。而 Systemd 通过不同的文件后缀区分这些配置文件。
支持的12种 Unit 文件类型
.timer:配置在特定时间触发的任务,替代了 Crontab的功能
.service:封装守护进程的启动、停止、重启和重载操作,是最常见的一种 Unit 文件
.target:用于对 Unit 文件进行逻辑分组,引导其他 Unit 的执行
.automount:用于控制自动挂载文件系统,相当于autofs 服务。
.device: 对于/dev目录下的设备,主要用于定义设备之间的依赖关系
.mount:定义系统结构层次中的一个挂载点,替代过去的 /etc/fstab 配置文件
.scope: Systemd运行时产生的文件,描述一些系统服务的分组信息
.slice:用于表示一个 cGroup 的树,通常用户不会自己创建
.snapshot
.socket
.swap
目录
按照约定,放置在指定的是哪个系统目录之一中。优先级高的目录里的文件会被使用。
- /etc/systemd/system :系统或者用户自定义的配置文件(优先级最高)
- /run/systemd/system :软件运行时生成的配置文件
- /usr/lib/systemd/system :系统或者第三方软件安装时添加的配置文件
文件结构
例如:
[Unit]
Description=Hello World
After=docker.service
Requires=docker.service
[Service]
TimeoutStartSec=0
ExecStartPre=-/usr/bin/docker kill busybox1
ExecStartPre=-/usr/bin/docker rm busybox1
ExecStartPre=/usr/bin/docker pull busybox
ExecStart=/usr/bin/docker run --name busybox1 busybox /bin/ sh -c "while true; do echo Hello World; sleep 1; done"
ExecStop="/usr/bin/docker stop busybox1"
ExecStopPost="/usr/bin/docker rm busybox1"
[Install]
WantedBy=multi-user.target
Unit 文件可以分为三个配置区段:
- Unit 段:所有 Unit 文件通用,配置服务的描述、依赖和随系统启动的方式。
- Service 段:后缀为 .service 特有的,用于定义服务的具体管理和操作方法。
- Install 段: 和 Unit 段 作用相同。
Unit 段
- Description
- Documentation
- Requires
- Wants
- After
- Before
- Binds To
- Part Of
- OnFailure
- Conflicts
Install 段
这部分配置的目标通常是特定运行目标的 .target 文件,用来使得服务在系统启动时自动运行。这个区段可以包含三种启动约束:
- WantedBy
- RequiredBy
- Also 当前 Unit enable/disabled时,同时 enable/disable 其他 Unit
- Alias 启动的别名
systemctl list-units –type=target # 获取当前正在使用的运行目标
Service 段
声明周期相关:
- type :启动时的进程行为
- simple: 默认值,执行 execstart 指定的命令,启动主进程
- forking 从父进程创建子进程,创建后父进程会立即突出
- oneshot 一次性进程, systemd 会等当前服务退出,再继续往下执行
- dbus
- notify 当前服务启完毕,通知 systemd,再继续往下执行
- idle 若有其他任务执行完毕,当前服务才会运行
- RemainAfterExit
- ExecStart
- ExecStartPre
- ExecStartPos
- ExecReload
- ExecStop
- ExecStopPost
- RestartSec
- Restart 重新启动, always on-success on-failure on-abnormal on-abort on-watchdog
- TimeoutStartSec 启动服务时等待的秒数,一般docker容器拉镜像时间较长设置0,关闭超时检测
- TimeoutStopSec 停止服务时的等待秒数,如果超过这个时间仍然没有停止,syystemd会使用 sigkill 信号强行杀死服务的进程。
服务上下文配置相关
- Environment 为服务指定环境变量
- EnvironmentFile
- Nice 服务进程的优先级,越小越高,默认为0,范围是 -20~19
- WorkingDirectory
- RootDirectory 服务进程的根目录
- User
- Group
:如果在 ExecStart、ExecStop 等属性中使用了 Linux 命令,则必须要写出完整的绝对路径。对于 ExecStartPre 和 ExecStartPost 辅助命令,若前面有个 “-” 符号,表示忽略这些命令的出错。
Systemd 资源管理
Systemctl 命令:
# 列出正在运行的 Unit
systemctl list-units
# 列出所有Unit,包括没有找到配置文件的或者启动失败的
systemctl list-units --all
# 列出所有没有运行的 Unit
systemctl list-units --all --state=inactive
# 列出所有加载失败的 Unit
systemctl list-units --failed
# 列出所有正在运行的、类型为 service 的 Unit
systemctl list-units --type=service
# 查看 Unit 配置文件的内容
systemctl cat docker.service
查看 Unit 的状态:
# 显示系统状态
systemctl status
# 显示单个 Unit 的状态
systemctl status bluetooth.service
# 立即启动一个服务
sudo systemctl start apache.service
# 立即停止一个服务
sudo systemctl stop apache.service
# 重启一个服务
sudo systemctl restart apache.service
# 杀死一个服务的所有子进程
sudo systemctl kill apache.service
# 重新加载一个服务的配置文件
sudo systemctl reload apache.service
# 重载所有修改过的配置文件
sudo systemctl daemon-reload
# 显示某个 Unit 的所有底层参数
systemctl show httpd.service
# 显示某个 Unit 的指定属性的值
systemctl show -p CPUShares httpd.service
# 设置某个 Unit 的指定属性
sudo systemctl set-property httpd.service CPUShares=500
查看 Unit 的依赖关系:
# 列出所有依赖,默认不会列出 target 类型
systemctl list-dependencies nginx.service
# 列出所有依赖,包括 target 类型
systemctl list-dependencies --all nginx.service
Systemd 工具集
- systemctl:用于检查和控制各种系统服务和资源的状态
- bootctl:用于查看和管理系统启动分区
- hostnamectl:用于查看和修改系统的主机名和主机信息
- journalctl:用于查看系统日志和各类应用服务日志
- localectl:用于查看和管理系统的地区信息
- loginctl:用于管理系统已登录用户和 Session 的信息
- machinectl:用于操作 Systemd 容器
- timedatectl:用于查看和管理系统的时间和时区信息
- systemd-analyze 显示此次系统启动时运行每个服务所消耗的时间,可以用于分析系统启动过程中的性能瓶颈
- systemd-ask-password:辅助性工具,用星号屏蔽用户的任意输入,然后返回实际输入的内容
- systemd-cat:用于将其他命令的输出重定向到系统日志
- systemd-cgls:递归地显示指定 CGroup 的继承链
- systemd-cgtop:显示系统当前最耗资源的 CGroup 单元
- systemd-escape:辅助性工具,用于去除指定字符串中不能作为 Unit 文件名的字符
- systemd-hwdb:Systemd 的内部工具,用于更新硬件数据库
- systemd-delta:对比当前系统配置与默认系统配置的差异
- systemd-detect-virt:显示主机的虚拟化类型
- systemd-inhibit:用于强制延迟或禁止系统的关闭、睡眠和待机事件
- systemd-machine-id-setup:Systemd 的内部工具,用于给 Systemd 容器生成 ID
- systemd-notify:Systemd 的内部工具,用于通知服务的状态变化
- systemd-nspawn:用于创建 Systemd 容器
- systemd-path:Systemd 的内部工具,用于显示系统上下文中的各种路径配置
- systemd-run:用于将任意指定的命令包装成一个临时的后台服务运行
- systemd-stdio- bridge:Systemd 的内部 工具,用于将程序的标准输入输出重定向到系统总线
- systemd-tmpfiles:Systemd 的内部工具,用于创建和管理临时文件目录
- systemd-tty-ask-password-agent:用于响应后台服务进程发出的输入密码请求
3.6 - 服务器配置 SSH 公钥登陆
服务器配置 SSH 公钥登陆
服务器配置 SSH 公钥登陆
- Xshell 工具可以生成公私钥对,输入密码加密。
- 在服务器端编辑 /etc/ssh/sshd_conf 。
RSAAuthentication yes #开启RSA认证 PubkeyAuthentication yes #开启公钥认证 AuthorizedKeysFile .ssh/authorized_keys #设置公钥的保存位置,默认为用户目录下的.ssh目录,没有可自行创建。 - 将保存好的 .pub 公钥文件 上传到服务器,保存在 ~/.ssh/authorized_keys 文件中。
- 设置权限
chmod 700 .ssh chmod 600 ~/.ssh/authorized_keys - 重启 sshd 服务以使配置生效
service sshd restart - 在测试公钥登陆成功后可以再次编辑 /etc/ssh/sshd_config 文件,关闭密码登陆,提高安全性。
PasswordAuthentication no
3.7 - 调度算法
操作系统的三大调度机制,分别是 进程调度、页面置换、磁盘调度算法。
操作系统的三大调度机制,分别是 进程调度、页面置换、磁盘调度算法。
进程调度算法
进程调度算法也称为 CPU 调度算法,毕竟进程是由 CPU 调度的。
当 CPU 空闲时,操作系统就会选择内存中的某个 [就绪状态] 的进程,并给其分配 CPU。
什么时候发生 CPU 调度?
- 当进程从运行状态转到等待状态 - 非抢占式调度
- 当进程从运行状态转到就绪状态 - 抢占式调度
- 当进程从等待状态转到就绪状态 - 抢占式调度
- 当进程从运行状态转到终止状态 - 非抢占式调度
非抢占式的意思是,当进程正在运行时,就会一直运行,知道该进程完成或者发生某个事件而被阻塞时,才会把 CPU 让给其他进程。 抢占式的意思是,进程正在运行时,可以被打断,使其把 CPU 让给其他进程。那抢占的原则一般有三种,分别是时间片原则、优先权原则、短作业优先原则。
常见的调度算法:
- 先来先服务调度算法
- 最短作业优先调度算法
- 高响应比优先调度算法
- 时间片轮转调度算法
- 最高优先级调度算法
- 多级反馈队列调度算法
内存页置换算法
内存页置换算法的功能是,当出现缺页异常,需要调入新页面而内存已满时,选择被置换的物理页。 也就是说选择一个物理页换出到磁盘,然后把需要访问的页面换入到物理页。
算法的目标是,尽可能少的换入和换出的次数,常见的算法有:
- 最佳页置换算法
- 先进先出置换算法
- 最近最久未使用的置换算法
- 时钟页置换算法
- 最不常用置换算法
磁盘调度算法
3.8 - Overlay2
Overlay2
Docker 的存储驱动 Overlay2,可以通过 storage-driver 参数进行指定,也可以在 /etc/docker/daemon.json 文件中通过 storage-driver 字段进行设置。
存储驱动的作用
Docker 将容器镜像做了分层存储,每个层相当于包含着一条 Dockerfile 的指令。而这些层在磁盘上存储方式,已经在启动容器时,如何组织这些层,并提供可写层,便是存储驱动的主要作用。
不同的存储驱动实现不同,性能也有差异,同时使用不同的存储驱动会导致占用的磁盘空间有所不同。
驱动
- overlay2
- fuse-overlayfs
- btrfs
- zfs
- aufs
- overlay
- devicemapper
- vfs
OverlayFS
overlay2 是 overlay 的升级版,这两个存储驱动所用的都是 OverlayFS。它的出现是为了解决 overlay 存储驱动 inode 耗尽问问题。
启动一个容器后,查看 mount 挂载
$ mount |grep overlay
overlay on /var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a/merged type overlay
(rw,relatime,
lowerdir=/var/lib/docker/overlay2/l/VVZTUGALNCARSF7HMUB445JPUY:/var/lib/docker/overlay2/l/G3PPKI2BXA3PKTPL7VURBQVVKD:/var/lib/docker/overlay2/l/7NVHGK2ITPX2UT2YGDAJFJE2QD:/var/lib/docker/overlay2/l/GZGJV5VQ4T2ZGCCMGFKXOESBQP:/var/lib/docker/overlay2/l/PRL3DYKGN4DW6BAEZZ3B2YMPMZ:/var/lib/docker/overlay2/l/JT7YW37MP5DRFGKGMD3STR64HG:/var/lib/docker/overlay2/l/VVD7Z66THINOLXHB3V3UHUT5K7,
upperdir=/var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a/diff,
workdir=/var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a/work)
- 查看 merged 目录,为容器根目录,可以通过写文件测试。
- lowerdir 是 mount 中指定的目录。
- upperdir
- workdir
查看上级目录
$ ls /var/lib/docker/overlay2/00ba47aabb576aee7cd3ed472f825427050eb44dc909af8dbf667d3619f4f66a
diff link lower merged work
- lower 是基础层,可以包含多个 lowerdir
- diff 是可写层,即挂载时的 upperdir,在容器内变更的文件都在这层存储
- merged 是最终合并的结果,即容器给我们呈现的结果
Overlay2
经过上面对 Docker 启动容器之后挂载的 OverlayFS 的介绍后, Overlay2 的工作流程应该会比较清楚。
将镜像各层为 lower 基础层,同时增加 diff 这个可写层,通过 OverlayFS 的工作机制,最终将 merged 作为容器内的文件目录展示给用户。
其中对 lower 的深度有硬编码的限制,当前限制为 128 。如果在使用的过程中遇到错误,有可能表示超过了最大深度限制,必须减少层数。
3.9 - OCI
OCI
为了推进容器化技术的工业标准化,在2015年在 DockerCon 上一些公司共同宣布成立开放容器项目(OCP),后更名为 OCI。
OCI(Open Container Initiative)
主要的目标是建立容器格式和运行时的工业开放通用标准。
OCI指定的标准有三个:
- runtime-spec
- image-spec
- distribution-spec
3.10 - tcpdump 抓包
tcpdump 抓包
Tcpdump 是一个网络数据包截获分析工具。支持针对网络层、协议、主机、网络或者端口的过滤。并提供and or not 等逻辑语句。
tcpdump tcp -i eth1 -t -s 0 -c 100 and dst port ! 22 and src net 192.168.1.0/24 -w ./tag.cap
解释如下:
- tcp :过滤数据包的类型,放到第一个参数位置, icmp arp tcp udp 等
- -i eth1 :只抓经过接口 eth1 的包
- -t :不显示时间戳
- -s 0 :抓完整的数据包,因为抓取数据包时默认的长度为68字节
- -c 100 :只抓取 100 个数据包
- dst port ! 22 : 不抓取目标端口是22的数据包
- src net 192.168.1.0/24 : 数据包的源网络地址是 192.168.1.0
- -w ./tag.cap 保存成 cap 文件,方便 wireshark 分析
3.11 - 容器网络和iptables
容器网络和iptables
容器网络和iptables
启动一个容器,查看iptables
$ iptables-save
# Generated by iptables-save v1.8.4 on Thu Jan 12 10:28:13 2023
*security
:INPUT ACCEPT [3207420:579585381]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [3205687:578296425]
COMMIT
# Completed on Thu Jan 12 10:28:13 2023
# Generated by iptables-save v1.8.4 on Thu Jan 12 10:28:13 2023
*raw
:PREROUTING ACCEPT [3281739:594537318]
:OUTPUT ACCEPT [3205687:578296425]
COMMIT
# Completed on Thu Jan 12 10:28:13 2023
# Generated by iptables-save v1.8.4 on Thu Jan 12 10:28:13 2023
*nat
:PREROUTING ACCEPT [5948:1205704]
:INPUT ACCEPT [120:27480]
:OUTPUT ACCEPT [21:1239]
:POSTROUTING ACCEPT [21:1239]
:DOCKER - [0:0]
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
COMMIT
# Completed on Thu Jan 12 10:28:13 2023
# Generated by iptables-save v1.8.4 on Thu Jan 12 10:28:13 2023
*mangle
:PREROUTING ACCEPT [3281739:594537318]
:INPUT ACCEPT [3207420:579585381]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [3205687:578296425]
:POSTROUTING ACCEPT [3205687:578296425]
COMMIT
# Completed on Thu Jan 12 10:28:13 2023
# Generated by iptables-save v1.8.4 on Thu Jan 12 10:28:13 2023
*filter
:INPUT ACCEPT [187:49960]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [68:7214]
:DOCKER - [0:0]
:DOCKER-ISOLATION-STAGE-1 - [0:0]
:DOCKER-ISOLATION-STAGE-2 - [0:0]
:DOCKER-USER - [0:0]
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
COMMIT
# Completed on Thu Jan 12 10:28:13 2023
iptables 基础
一个 iptables 上可能包含多个表,表可能包含多个链。链可以是内置的或者用户定义的。 链可能包含多个规则,规则是为数据包定义的。
表是一堆链,链是一堆防火墙规则。
iptables -> tables -> Chains -> Rules
Iptables 表和链
四个内置表
1. 过滤表
默认表,表内有内置链。
- INPUT链 - 传入防火墙
- OUTPUT链 - 从防火墙传出
- FORWARD链 - 本地服务器上另一个NIC的数据包。对于通过本地服务器路由的数据包。
2. NAT表
NAT表具有以下内置链
- PREROUTING 链 - 在路由之前更改数据包。 用于 DNAT (目标NAT)
- POSTROUTING 链 - 在路由后更改数据包。用于SNAT(源 NAT)
- OUTPUT 链 - 防火墙上本地生成的数据包的NAT。
3. Mangle表
用于专门的数据包更改,改变TCP报文头中的QOS位,具有以下内置链:
Docker 网络与 iptables
dockerd daemon 参数有 –iptables 参数,默认为 true ,默认添加 iptables 规则。如果启动时添加 –iptables=false 参数,默认没有任何规则。
利用 docker in docker 启动一个镜像 docker:dind 的容器,进入之后查看 iptable 规则。
# Generated by iptables-save v1.8.6 on Thu Jan 12 02:35:29 2023
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
:DOCKER - [0:0]
:DOCKER-ISOLATION-STAGE-1 - [0:0]
:DOCKER-ISOLATION-STAGE-2 - [0:0]
:DOCKER-USER - [0:0]
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
COMMIT
# Completed on Thu Jan 12 02:35:29 2023
# Generated by iptables-save v1.8.6 on Thu Jan 12 02:35:29 2023
*nat
:PREROUTING ACCEPT [0:0]
:INPUT ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
:DOCKER - [0:0]
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.18.0.0/16 ! -o docker0 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
COMMIT
# Completed on Thu Jan 12 02:35:29 2023
DOCKER-USER 链
-A FORWARD -j DOCKER-USER
...
-A DOCKER-USER -j RETURN
以上规则是在 filter 表中生效的:
- 第一条表示流量进入 FORWARD 链后,直接进入到 DOCKER-USER 链
- 最后一条表示流量进入 DOCKER-USER 链处理后,可以再 RETURN 回原先的链,进行后续规则的匹配。
这个其实是 Docker 预留的一个链,供用户自行配置的一些额外的规则。
Docker 默认的路由规则是允许所有客户端访问的,如果 Docker 在公网上运行,或者希望避免 Docker 中的容器被局域网中其他客户端访问,那么需要在这里添加一条规则。
iptables -I DOCKER-USER -i
! -s xxx.xxx.xxx.xxx -j DROP (仅允许 xxx.xxx.xxx.xxx 访问)
Docker 在重启之类的操作时,会进行 iptables 相关规则的清理和重建,但是 DOCKER-USER 链中的规则可以持久化,不受影响。
DOCKER-ISOLATION-STAGE-1/2 链
这两条链主要是分两个阶段进行了桥接网络隔离。
相同 network 的容器是可以 ping 通的,不同 network 的容器则不能。
Docker 链
使用最频繁,规则最多。如果误删链中内容,可能会导致容器的网络出现问题,尝试手动修改和重启Docker。
Docker 分别在 filter 和 nat 表增加了规则,具体含义如下:
filter 表中新增容器的目标地址,目标端口是映射端口的 TCP 协议被接收。
nat 表 上提供了 Docker 容器端口转发的能力,将访问本地地址端口流量的目标地址换成容器的 ip:port 地址。
containerd 与 iptables
k8s1.24不支持 dockershim,要将容器的运行时切换到 contained,在 contained 中是无法进行端口映射的。 自带的 ctr 命令不支持端口映射,那么想用的时候,怎么做呢?
一种是自己管理 iptables 规则,比较繁琐。 另一种方式是使用 nerdctl 这个专门为 containerd 做的,兼容 Docker CLI 的工具。
nerdctl run 0d –name redis -p 6379:6379 redis:alpine