Java
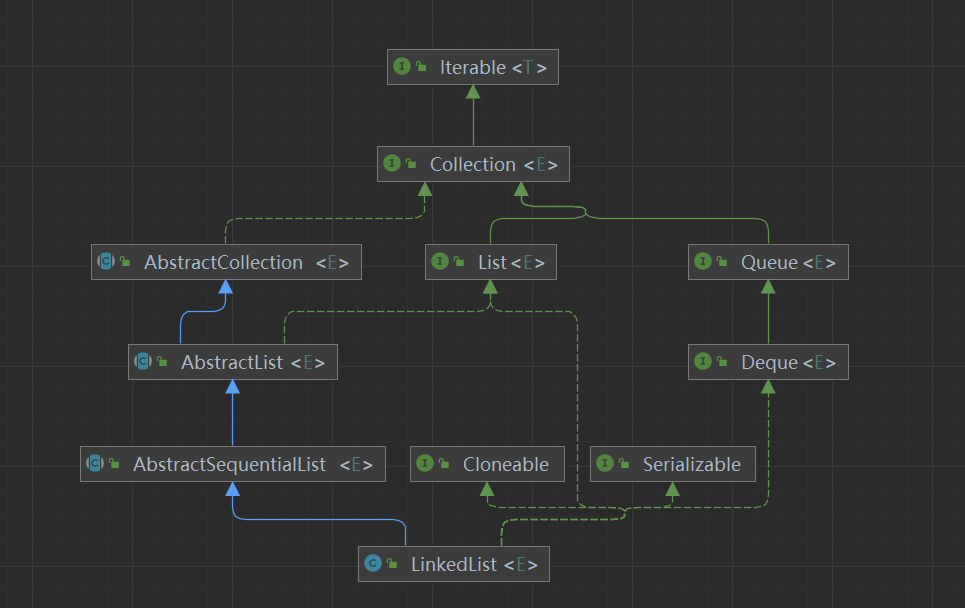
1 - 集合Collection
容器主要包括 Collection 和 Map 两种, Collection 存储着对象的集合,而 Map 存储着键值对的映射表。
Set
Treeset
基于红黑树实现,支持有序操作,例如根据一个范围查找元素的操作,查找效率不如 HashSet。 HashSet 查找的时间复杂度为 O(1),TreeSet 则为O(logN)。
HashSet
基于哈希表的实现,支持快速查找,但是不支持有序性操作。遍历得到的结果顺序不确定。
List
ArrayList
基于动态数组实现,保证顺序支持随机访问。
有一个 capacity,表示底层数据的实际大小。当添加元素,容量不足时,容器会自动增大底层数组的大小。 没有实现同步(synchronized),如果需要多个线程并发访问,需要用户控制,也可以使用 Vector 替代。
Vector
和 ArrayList 类似,是线程安全的。
LinkedList
基于双向链表实现,只能顺序访问,可以快速的在中间插入和删除元素。 不仅如此,LinkedList还可以当 栈 或者 队列(首选ArrayDeque)
解释一下删除remove(int index) 方法:
- 根据index获取元素, index 与 sise/2 作比较,小于一半的时候从前向后遍历,大于一半的时候从后向前遍历
- 删除获取的元素,修改前后指针的指向
插入add()方法默认是插入到最后,还可以根据index插入。
clear()方法是将内置的元素引用全部清空,如next,prev,item。
Queue
throw exception return special value
Insert add(e) offer(e) Remove remove() poll() Examine element() peek()
LinkdList
实现双向队列。
queue的几个方法也是常规用法。
LinkedList list = new LinkedList
(); //只有这样写才能使用到queue的方法。
Deque
双端队列,多一些方法,常规用法。
PriorityQueue
基于堆结构实现,用来实现优先队列。 优先队列的作用是保证每次取出的元素都是队列中权值最小的,元素大小的评判可以通过元素本身的自然顺序,也可以通过构造时传入的比较器。
Map
TreeMap
基于红黑树实现。
HashMap
基于数组+链表+红黑树实现,线程安全使用 ConcurrentHashMap。
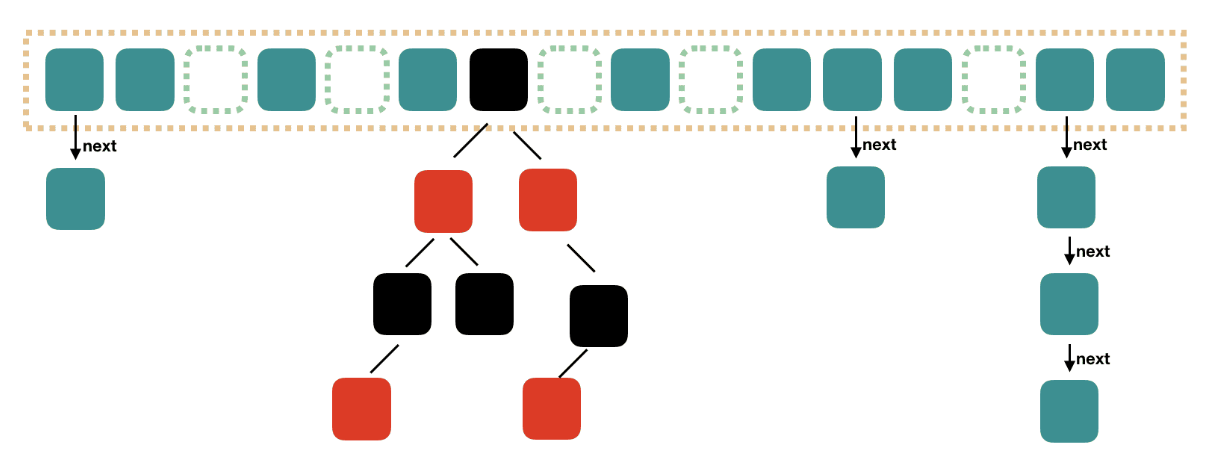
LinkedHashMap
使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
2 - jdbc
什么是数据库连接池,解决什么问题?
连接池基本的思想是在系统初始化的时候,将数据库连接作为对象存储在内存中。当用户需要访问数据库时,从池中取出一个已建立的空闲连接对象。使用完后放回池中,以供下一个请求访问使用。
springboot 默认连接池 hikari 配置
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test?allowPublicKeyRetrieval=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: xxx
type: com.zaxxer.hikari.HikariDataSource
hikari:
# 连接池名称
pool-name: pool-demo
# 最小连接数,一直保持的连接
minimum-idle: 5
# 空闲连接存活最大时间,默认10分钟
idle-timeout: 600000
# 最大连接数,默认20
maximum-pool-size: 20
# 连接池中连接的最长生命周期,默认30分钟
max-lifetime: 1800000
# 数据库连接超时时间,默认30秒
connection-timeout: 30000
# 此属性控制从池返回的连接的默认自动提交行为,默认值:true
auto-commit: true
connection-test-query: select 1
为什么称为默认连接池:
- 字节码精简
- 优化代理和拦截器
- 自定义数组类型(FastStatementList 替代 ArrayList)
- 自定义集合类型(ConcurrentBag)
3 - spring
spring 框架
模板:
- 函数模板返回值和参数 返回值是void 参数一般不确定,可以先写逻辑,然后需要参数再填
- 终止条件 一般是到了叶子结点,也就是满足条件的一条答案,把这个答案存起来,并结束本层递归。 if(终止条件){ 存放结果; return; }
- 遍历过程 一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成树的深度。 for(选择:本层集合元素(树中节点孩子的数量就是集合的大小)){ 处理节点; backtracking(路径,选择列表)//递归 回溯,撤销处理结果 }
for循环可以理解是横向遍历,backtracking是纵向遍历。
分析完过程,整个框架如下:
void backtracking(参数){
if(终止条件){
存放结果;
return;
}
for(选择:本层集合元素(树中节点孩子的数量就是集合的大小)){
处理节点;
backtracking(路径,选择列表);//递归
回溯,撤销处理结果
}
}
4 - 虚拟机
JVM 虚拟机
java 内存模型
jmm 体现在以下三个方面:
- 原子性:保证指令不会受到上下文切换的影响;
- 可见性:保证指令不会受到cpu缓存的影响;
- 有序性:保证指令不会受并行优化的影响;
volaile
解决了可见性和有序性,通过内存屏障实现的。没有解决原子性,即不能通过该关键字实现线程安全。
无锁-CAS
compare and swap
为变量赋值时,从内存中读取到的值为v,获取到要交换的新值n,执行 compareAndSwap() 方法时,比较v和当前内存中的值是否一致,如果一致将n和v交换,如果不一致,则自旋重试。
casd底层是cpu层面的,即时不适用同步锁也会保证元资信的操作。
线程池
- corePoolSize 核心线程数
- maximumPoolSize 最大线程数
- keepAliveTime 救急线程(max-core)空闲时间
- unit 救急线程(max-core)空闲时间单位
- workQueue 阻塞队列
- threadFactry 创建线程的工厂,主要定义线程名
- handler 拒绝策略
线程池的状态
- Running 正常接收任务,正常处理任务
- Shutdown 不接收任务,会执行完正在执行的任务,处理阻塞队列中的任务
- stop 不接收任务,中断正在执行的任务,放弃处理阻塞队列中的任务
- Tidying 即将进入终结
- Termitted 终结状态
线程池的主要流程
- 创建线程池后,线程池的状态是 Running,该状态下才能有以下步骤。
- 提交任务,线程池创建线程去处理。
- 当线程池的工作线程数达到 corePoolSize 时,继续提交任务会进入阻塞队列。
- 当阻塞队列队列装满时,继续提交任务,会创建救急线程来处理。
- 当线程池中的线程数达到max时,会执行拒绝策略。
- 当线程取任务的时间达到 keepAliveTime 时还没有取到任务,工作线程数大于 corePoolSize 时,会回收该线程。
拒绝策略
- 调用者抛出 RejectedExecutionException(默认策略)。
- 让调用者运行任务。
- 丢弃此次任务。
- 丢弃阻塞队列中最早的任务,加入该任务。