语言的语法,技术细节
1 - Golang
没有项目做,语法很快就会忘记,这里把常用的语法记下来
1.1 - 语法
golang 语法
变量声明
指定变量类型,如果没有初始化,则变量默认为零值。 如果变量已经使用 var 声明过了,再使用 := 声明变量,就产生编译错误。
默认的零值:
- 数值类型为0
- 布尔类型为 false
- 字符串为 "" (空字符串)
- 以下几种类型为nil
- var a *int
- var a []int
- var a map[string] int
- var a chan int
- var a func(string) int
- var a error // error 是接口
值类型和引用类型
像 int float bool string 这些类型都是值类型,使用这些类型的变量直接指向存在内存中的值。 当使用等号 = 将一个变量的值赋给另一个变量时,如: j = i ,实际上是在内存中将 i 的值进行了拷贝。
可以通过 &i 来获取 i 的内存地址,值类型的变量的值存储在堆中。
通常更复杂的数据会使用多个字,这些数据一般使用引用类型保存。 一个引用类型的变量 r1 存储的是 r1 的值所在的内存地址,或者内存地址中第一个字所在的位置。 这个内存地址被称为指针,这个指针实际上也是被存在另外的某一个值中。
常量
常量是一个简单值的标识符,在程序运行时,不会被修改的值。 常量中的数据类型只能是 布尔 数字型(整数型、浮点和复数)和字符串。
定义的格式:
const identifier [type] = value
可以省略 [type] ,编译器可以根据变量的值来推断其类型。 多个相同类型的声明可以简写为:
const c_name1, c_name2 = value1, value2
运算符
比较重要的两个:
- & 返回变量存储地址
- 指针变量
如:
a := 4
b = &a
fmt.Println(b) # 0xc00000a0c8
fmt.Println(*b) # 4
可以记忆为: 星号是变量
函数
函数参数,有两种方式来传递:
- 值传递:在调用函数时将实际参数复制一份传递到函数中,这样在函数中对参数进行修改,不会影响到实际参数。
- 引用传递:引用传递时指将实际参数的地址传递到函数中,在函数中对参数进行修改,将影响到实际参数。
函数用法:
- 函数作为另一个函数的实参
- 闭包
- 方法
数组
声明需要指定元素类型以及元素个数,在声明的时候指定大小,每个元素会根据数据类型进行默认初始化,对于整数类型,初始化为0。
var arrayName [size]dataType
还可以使用初始化列表来初始化数组的元素:
numbers := [5] int{1,2,3,4,5}
还得理解:
- 多维数组
- 向函数传递数组
指针
指针变量指向了一个值的内存地址。类似于变量和常量,在使用指针前需要声明指针,声明格式如下:
var var_name *var-type
eg:
var ip *int
var fp *float32
指针使用流程:
- 定义指针变量
- 为指针变量赋值
- 访问指针变量中指向地址的值
在指针类型前面加上 * 号来获取指针所指向的内容。
var a int= 20 /* 声明实际变量 */
var ip *int /* 声明指针变量 */
ip = &a /* 指针变量的存储地址 */
空指针
当一个指针被定义后没有分配到任何变量时,它的值是nil。nil指针也被称为空指针。 一个空指针通常缩写为 ptr
var ptr *int
空指针判断:
- if(ptr != nil)
- if(ptr == nil)
结构体
数组存储同一类型的数据,结构体中可以为不同项定义不同的数据类型。
type struct_type struct {
age int
}
结构体指针:
var struct_pointer *Books
struct_pointer = &Book
切片
切片是对数组的抽象。
Go 数组的长度不可改变,在特定场景中不适用。相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
定义切片:
var identifier []type
切片不需要说明长度,或者使用make()函数来创建切片:
var slice1 []type = make([]type, len)
slice2 := make([]type, len)
slice3 := make([]type,len, capacity) #容量是可选参数
初始化切片,其中cap=len=3:
s := [] int {1,2,3}
切片在未初始化之前默认是nil,长度为0。
隔断: 通过设置下限以及上限来设置截取切片。
append()和copy()函数: 如果想增加切片的容量,创建一个新的更大的切片把原切片内容都拷贝过来。
范围
Go 语言中 range 关键字在于 for 循环中迭代数组、切片、通道和集合的元素,在数组和切片中返回元素的索引和索引对应的值,在集合中返回 key - value 对。
for key,value := range oldMap {
newMapp[key] = value
}
在上述代码中,key和 value 都是可以省略的。
for key := range oldMap #省略 val
for ——,val:= range oldMap # 省略 key
for key,_ := range oldMap # 省略val
Map 集合
无序的键值对的集合。通过 key 快速检索数据,key 类似于索引,指向数据的流。
定义 Map:
使用内建函数 make 或使用 map 关键字来定义 Map
map_variable := make(map[keyType]ValueType, initialCapacity)
当 Map 中的键值对数量达到容量时,Map会自动扩容。 如果不指定 initialCapacity,Go 语言会根据实际情况选择一个合适的值。
# 空 map
map1 := make(map[string]int)
# 初始化容量是10
map2 := make(map[string]int,10)
# 字面量创建 Map
map3 := map[string]int{
"a": 1,
"b": 2,
"c": 3,
}
# 获取元素
v1 := map3["a"]
v2, ok := map3["b"]
# 修改元素
m["a"] =5
# 获取Map的长度
len := len(m)
# 删除
delete(m,"a")
# 遍历
for k ,v := range m{
fmt.Printf("key=%s, value=%d\n",k,v)
}
类型转换
类型转换的基本格式如下:
type_name(expression)
type_name 为类型, expression 为表达式。
# 整数转浮点型
var a int = 10;
var b float64 = float64(a)
# 字符串类型转换
var str string = "10"
var num int
num,_ = strconv.Atoi(str) # 第二个是可能的错误
# 整数转字符串
num := 123
str := strconv.Itoa(num)
# 字符串转为浮点数
str := "3.14"
num,err := strconv.ParseFloat(str,64)
# 接口类型转换 value.(Type)
var i interface{} = "hi"
str,ok := i.(string)
错误处理
error类型是一个接口类型
type error interface {
Error() string
}
函数通常在最后的返回值中返回错误信息。使用 errors.New 可返回一个错误信息。
error.New("this is a error.")
并发
通过 go 关键字来开启 goroutine 即可。 goroutine 是轻量级线程,调度是由Golang 运行时进行管理的。
go 函数名(参数列表)
通道
通道是用来传递数据的一个数据结构。 通道可以用于两个 goroutine 之间通过传递一个指定类型的值来同步运行和通讯。操作符 <- 用于指定通道的方向用于发送和接收,如果未指定方向则是双向通道。
ch <- v // 把 v 发送给通道 ch
v := <- ch // 从 ch 接收数据,把值赋给 v
声明通道:
ch := make(chan int)
默认情况下,通道是不带缓冲区的。发送端发送数据,同时必须有接收端相应的接收数据。
1.2 - Log日志框架
选择一个合适的日志框架可以更好地管理和输出日志信息,以下列举了一些常用的日志框架。
本文介绍了一些常用的日志框架,并对比了它们的优缺点。
1. logrus
logrus 是 Go 语言生态中最流行的日志框架。它提供了一些简单易用的 API,可以满足一般的日志需求。
- 优势:支持日志级别、hook、多种格式化输出
- 使用场景:适合需要结构化日志输出和较为复杂的日志管理的项目
2. zap
zap 是 Uber 开源的日志框架。它提供了高性能、结构化日志输出、可扩展性强、易用性高的特点。
- 优势:主打高性能,结构化和轻量级,适合性能敏感的项目
- 使用场景:当性能是首要因素时,尤其是高并发应用推荐使用
3. zerolog
提供低内存和高性能功能,支持json格式输出,针对嵌入式环境和高性能应用优化
- 场景:对性能有高追求的应用
4. k-log
k-log 是 Kubernetes 社区开源的日志框架。它提供了日志级别、格式化输出、多路输出、日志文件分割等功能。
- 优势:支持日志级别、多路输出、日志文件分割、可扩展性强
- 使用场景:适合 Kubernetes 生态系统组件统一日志记录的项目
K-log 使用
import “k8s.io/klog/v2”
klong.InitFlags(nil) 初始化全局标志
Basic examples: glog.Info("Prepare to repel boarders") glog.Fatalf("Initialization failed: %s", err) See the documentation of the V function for an explanation of these examples: if glog.V(2) { glog.Info("Starting transaction...") } glog.V(2).Infoln("Processed", nItems, "elements")
2 - Java
Java
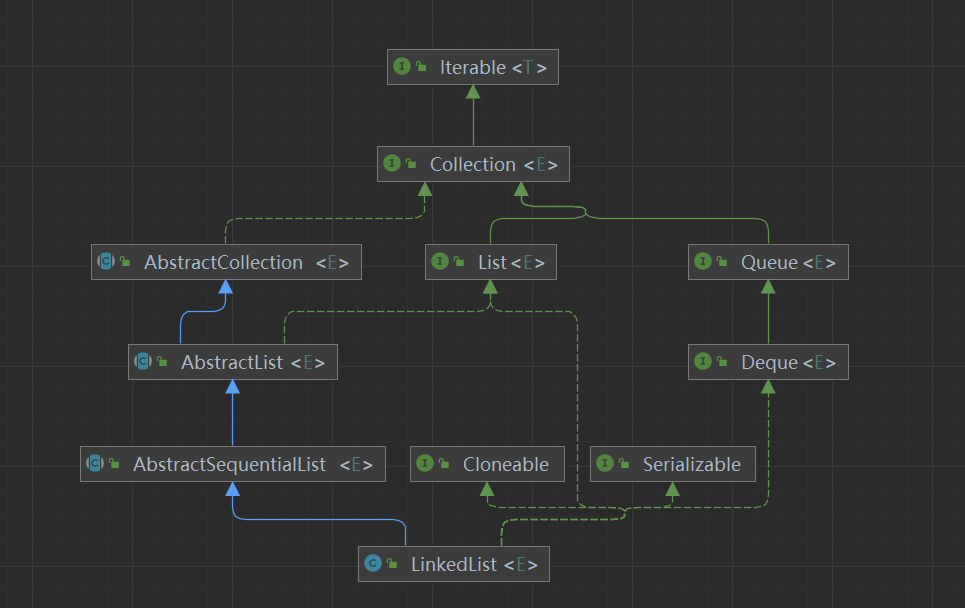
2.1 - 集合Collection
容器主要包括 Collection 和 Map 两种, Collection 存储着对象的集合,而 Map 存储着键值对的映射表。
Set
Treeset
基于红黑树实现,支持有序操作,例如根据一个范围查找元素的操作,查找效率不如 HashSet。 HashSet 查找的时间复杂度为 O(1),TreeSet 则为O(logN)。
HashSet
基于哈希表的实现,支持快速查找,但是不支持有序性操作。遍历得到的结果顺序不确定。
List
ArrayList
基于动态数组实现,保证顺序支持随机访问。
有一个 capacity,表示底层数据的实际大小。当添加元素,容量不足时,容器会自动增大底层数组的大小。 没有实现同步(synchronized),如果需要多个线程并发访问,需要用户控制,也可以使用 Vector 替代。
Vector
和 ArrayList 类似,是线程安全的。
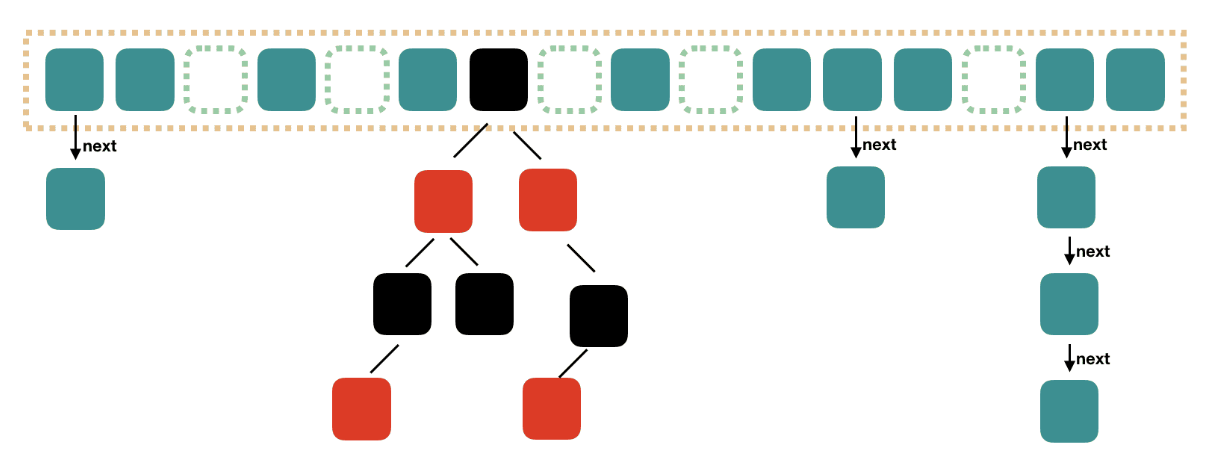
LinkedList
基于双向链表实现,只能顺序访问,可以快速的在中间插入和删除元素。 不仅如此,LinkedList还可以当 栈 或者 队列(首选ArrayDeque)
解释一下删除remove(int index) 方法:
- 根据index获取元素, index 与 sise/2 作比较,小于一半的时候从前向后遍历,大于一半的时候从后向前遍历
- 删除获取的元素,修改前后指针的指向
插入add()方法默认是插入到最后,还可以根据index插入。
clear()方法是将内置的元素引用全部清空,如next,prev,item。
Queue
throw exception return special value
Insert add(e) offer(e) Remove remove() poll() Examine element() peek()
LinkdList
实现双向队列。
queue的几个方法也是常规用法。
LinkedList list = new LinkedList
(); //只有这样写才能使用到queue的方法。
Deque
双端队列,多一些方法,常规用法。
PriorityQueue
基于堆结构实现,用来实现优先队列。 优先队列的作用是保证每次取出的元素都是队列中权值最小的,元素大小的评判可以通过元素本身的自然顺序,也可以通过构造时传入的比较器。
Map
TreeMap
基于红黑树实现。
HashMap
基于数组+链表+红黑树实现,线程安全使用 ConcurrentHashMap。
LinkedHashMap
使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
2.2 - jdbc
什么是数据库连接池,解决什么问题?
连接池基本的思想是在系统初始化的时候,将数据库连接作为对象存储在内存中。当用户需要访问数据库时,从池中取出一个已建立的空闲连接对象。使用完后放回池中,以供下一个请求访问使用。
springboot 默认连接池 hikari 配置
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test?allowPublicKeyRetrieval=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: xxx
type: com.zaxxer.hikari.HikariDataSource
hikari:
# 连接池名称
pool-name: pool-demo
# 最小连接数,一直保持的连接
minimum-idle: 5
# 空闲连接存活最大时间,默认10分钟
idle-timeout: 600000
# 最大连接数,默认20
maximum-pool-size: 20
# 连接池中连接的最长生命周期,默认30分钟
max-lifetime: 1800000
# 数据库连接超时时间,默认30秒
connection-timeout: 30000
# 此属性控制从池返回的连接的默认自动提交行为,默认值:true
auto-commit: true
connection-test-query: select 1
为什么称为默认连接池:
- 字节码精简
- 优化代理和拦截器
- 自定义数组类型(FastStatementList 替代 ArrayList)
- 自定义集合类型(ConcurrentBag)
2.3 - spring
spring 框架
模板:
- 函数模板返回值和参数 返回值是void 参数一般不确定,可以先写逻辑,然后需要参数再填
- 终止条件 一般是到了叶子结点,也就是满足条件的一条答案,把这个答案存起来,并结束本层递归。 if(终止条件){ 存放结果; return; }
- 遍历过程 一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成树的深度。 for(选择:本层集合元素(树中节点孩子的数量就是集合的大小)){ 处理节点; backtracking(路径,选择列表)//递归 回溯,撤销处理结果 }
for循环可以理解是横向遍历,backtracking是纵向遍历。
分析完过程,整个框架如下:
void backtracking(参数){
if(终止条件){
存放结果;
return;
}
for(选择:本层集合元素(树中节点孩子的数量就是集合的大小)){
处理节点;
backtracking(路径,选择列表);//递归
回溯,撤销处理结果
}
}
2.4 - 虚拟机
JVM 虚拟机
java 内存模型
jmm 体现在以下三个方面:
- 原子性:保证指令不会受到上下文切换的影响;
- 可见性:保证指令不会受到cpu缓存的影响;
- 有序性:保证指令不会受并行优化的影响;
volaile
解决了可见性和有序性,通过内存屏障实现的。没有解决原子性,即不能通过该关键字实现线程安全。
无锁-CAS
compare and swap
为变量赋值时,从内存中读取到的值为v,获取到要交换的新值n,执行 compareAndSwap() 方法时,比较v和当前内存中的值是否一致,如果一致将n和v交换,如果不一致,则自旋重试。
casd底层是cpu层面的,即时不适用同步锁也会保证元资信的操作。
线程池
- corePoolSize 核心线程数
- maximumPoolSize 最大线程数
- keepAliveTime 救急线程(max-core)空闲时间
- unit 救急线程(max-core)空闲时间单位
- workQueue 阻塞队列
- threadFactry 创建线程的工厂,主要定义线程名
- handler 拒绝策略
线程池的状态
- Running 正常接收任务,正常处理任务
- Shutdown 不接收任务,会执行完正在执行的任务,处理阻塞队列中的任务
- stop 不接收任务,中断正在执行的任务,放弃处理阻塞队列中的任务
- Tidying 即将进入终结
- Termitted 终结状态
线程池的主要流程
- 创建线程池后,线程池的状态是 Running,该状态下才能有以下步骤。
- 提交任务,线程池创建线程去处理。
- 当线程池的工作线程数达到 corePoolSize 时,继续提交任务会进入阻塞队列。
- 当阻塞队列队列装满时,继续提交任务,会创建救急线程来处理。
- 当线程池中的线程数达到max时,会执行拒绝策略。
- 当线程取任务的时间达到 keepAliveTime 时还没有取到任务,工作线程数大于 corePoolSize 时,会回收该线程。
拒绝策略
- 调用者抛出 RejectedExecutionException(默认策略)。
- 让调用者运行任务。
- 丢弃此次任务。
- 丢弃阻塞队列中最早的任务,加入该任务。
3 - Python
1989年底发明,第一个公开发行版发行于1991年。是一解释型、面相对象、动态数据类型的高级程序语言。
3.1 - 语法
python 语法
语法是学习一种语言的第一步,按照惯例,还是先总结备忘录。
简介
- 解释型,没有编译
- 交互式,在一个提示符 »> 之后可以执行代码
- 面向对象,可以定义类和对象,并使用继承,多态等特性。
基础语法
默认情况下,python3的源码都是以 UTF-8 编码,所有字符串都是 unicode 字符串。
单行注释以 # 开头,多行注释可以用多个 # 号,还有 ’’’ 和 “""。
行间缩进:使用缩进代表代码块,不需要使用大括号{}。缩进的空格是可变的,但是同一个代码块不许包含相同的缩进空格数。
if True:
print(1)
else:
print(2)
多行语句:太长的行最后可以使用反斜杠 ** 来实现多行语句。
数字(Number)类型:
- int
- bool
- float
- complex
字符串String:
- 单引号和双引号使用完全相同
- 使用三引号(’’’ 或者 “"")可以指定一个多行字符串
- 转义符 \
- 用 + 运算符连接在一起,用 * 运算符重复
- 索引,从左往右以 0 开始,从右向左以 -1 开始
- 字符串不可变
- 切边 str[start:end] 或者加上步长 str[start:end:step]
- 反斜杠可以用来转义,使用 r 可以让反斜杠不发生转义。 如 r"this is a line with \n” 则 \n 会显示,并不是换行
等待用户输入: \n\n 在结果输出前会输出两个新的空行,一旦用户按下 enter 键后,程序将退出。
导入:
- import xxx
- from xxx import …,…
import sys
from sys import argv,path # 导入特定的成员
数据类型
Python3 中常见的数据类型有:
- Number(数字)
- String(字符串)
- bool(布尔类型)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
List
写在方括号 [] 之间,用逗号分隔开的元素列表。
列表中的元素类型可以不相同,和字符串一样可以被索引和截断,列表被截断之后返回一个包含所需元素的新列表。 列表截取的语法格式如下:
变量[头下标:尾下标]
索引值是以0开始,-1为末尾的位置。 加号 + 是列表连接运算符,星号 * 是重复操作。
list = [1,2,3,4]
list.append(1) # 末尾添加
del list[2] # 删除第三个元素
len(list) # 长度
list1 + list2 # 组合
3 in [1,2,3] # 元素是否在列表中
for x in [1,2,3]: print(x,end="") # 迭代
list(seq) # 将元组转化哪位列表
min(list) # 列表元素最小值
max(list) # 列表元素最大值
list.reverse() #翻转
list.clear() #清空
list.copy() #复制列表
list.remove(obj) #移除列表中某个值的第一个匹配项
Tuple 元组
元组(tuple)与列表类似,不同之处在于元组的个数不能修改,值也不能修改。元组写在小括号 () 里,元素之间用逗号隔开。 元组中的元素类型也可以不相同。
tuple = ( ‘abcd’, 786 , 2.23, ‘runoob’, 70.2 )
虽然tuple的元素不可改变,但可以包含可变对象,如list。 构造包含0个或者1个 元素的元组比较特殊,有一些额外的语法规则:
tup1 = () #空元组
tup2 = (20,) #一个元素,需要在元素后面加个逗号
tup = (1,2,3,4,5)
tup[0] #访问
tup3 = tup1 + tup2 #创建一个新元组
del tup3 #删除,删除后再使用输出变量就会显示异常信息
3 in(1,2,3) #元素是否存在
for x in (1,2,3): print(x,end="")# 迭代
len(tuple) # 计算个数
max(tuple) #返回元组中最大值
min(tuple) #返回元组中最小值
tuple(iterable) #将可迭代系列转换为元组
Set 集合
无序,可变的数据类型,用于存储唯一的元素。 集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。 集合使用大括号{} 表示,元素之间使用逗号分隔。也可以使用 set()函数创建集合。
创建一个空集合必须使用 set() 而不是 {},因为 {}是用来创建一个空字典。
parame = {value01,value02,...}
#或者
set(value)
基本操作:
s = {'apple','pear'}
'pear' in s # 判断是否在集合中存在
s.remove('pear') # 移除
s.remove('abc') # 不存在发生报错
s.discard('abc') # 移除集合中的元素,如果不存在不会发生错误
s.pop() #随机删除结合中的元素
len(s) #集合s中的元素个数
s.clear() #清空集合
symmetric_difference() #返回两个集合中不重复的元素集合
symmetric_difference_update() #移除当前集合中在另外一个指定集合相同的元素,并将另一个集合中不同的元素插入到当前集合中
union() #返回两个集合的并集
update() #给集合添加元素
Dictionary 字典
字典是一种映射类型,用 {} 标识,是一个无序的键值对集合。 key必须使用不可变类型,key必须是唯一的。
创建字典:
dict1 = {} 或者使用内建函数 dict2 = dict()
如果用字典里没有的键来访问数据,会输出错误。
dict = {}
dict['one'] = "1 - 菜鸟教程" #添加
dict[2] = "2 - 菜鸟工具" # 添加,key可以是不同类型
del dict[2] # 删除键
dict.clear() # 清空字典
del dict # 删除字典
len(dict1) # 字典元素的个数
str(dict1) # 输出字典
dict.copy() # 浅复制
dict.fromkeys() #创建一个新字典,以序号seq为key,val为字典所有键对应的初始值
dict.get(key,default=None) #返回指定的值,键不在字典中返回 default 设置的默认值
key in dict #是否存在
dict.items() #以列表返回一个视图对象
dict.keys() #返回一个视图对象
dict.values() #返回一个视图对象
dict.setdefault(key,default=None) # 和get()类似,如果键不在字典中,将会添加键并将值设置为 default
数据类型转换
- int(x) 将x转换为一个整数
- str(x) 将对象x转换为字符串
- repr(x)
- eval(str)
- tuple(s) 将序列s转为一个元组
- list(s) 将序列s转换为一个列表
- set(s) 将序列s转为一个可变集合
- dict(d) 创建一个字典,d必须是一个(key,value)元组序列
- ord(x) 将字符转为它的整数值
流程控制
if 语句
if condition1:
statement_block_1
elif condition2:
statement_block_2
else:
statement_block_3
循环语句
使用 while 和 for 都可以,break是跳出当前循环体,不会执行else子句。continue 是跳出本次循环。
如果需要遍历数字,可以使用内置 range() 函数,它会生成数列, for i in range(5) 。
while 判断条件:
执行语句
else:
执行语句2
for <variable> in <sequence>:
<statements>
else:
<statements>
Python 推导式
推导式是一个独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。
python支持各种数据结构的推导式。
1. List 列表
[表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件]
# 过滤长度小于等于3的字符串列表,并且转换成大写的字母
names = ['Bob','Tom','alice']
new_names = [name.upper() for name in names if len(name) > 3]
print(new_names)
# 30以内可以被3整除的整数
a = [i for i in range(30) if i % 3 == 0]
print(a)
2. Dict 字典
{key_expr: value_expr for value in collection} 或者 {key_expr: value_expr for value in collection if condition}
demo = ['a','b','c']
my_dict = {key:len(key) for key in demo}
my_dict2 = {x:x**2 for x in (2,4,6)}
3. Set 集合
{ expression for item in Sequence } 或者 { expression for item in Sequence if conditional }
setnew = { i**2 for i in (1,2,3)}
print(setnew)
# 1,4,9
# 判断不是abc的字母输出
a = { x for x in 'abracadabra' if x not in 'abc'}
print(a)
# {'d','r'}
type(a)
# <class 'set'>
元组
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据结构,快速生成一个满足指定需求的元组。
( expression for item in Sequence ) 或者 ( expression for item in Sequence if conditional )
元组和list用法完全相同,元组推导式返回的结果是一个生成器对象。
a= (x for x in range(1,10))
print(a)
# <generator object <genexpr> at xxxx> 返回生成器对象
tuple(a) #使用 tuple()函数,可以直接将生成器对象转换成元组
# (1,2,3,4,5,6,7,8,9)
迭代器和生成器
迭代器
- iter()
- next()
list = [1,2,3,4]
it = iter(list)
print(next(it)) # 1
print(next(it)) # 2
for x in it:
print(x,end=" ")
把一个类作为迭代器使用需要在类中实现两个方法 iter() 和 next()。
python的构造函数 init() ,会在对象初始化的时候执行
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
myclass = MyNumbers()
myIter = iter(myclass)
print(next(myIter))
StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在 next() 方法中设置在完成指定循环后触发异常来结束迭代。
def __next__(self):
if self.a <= 20:
x = self.a
self.a += 1
return x
else:
raise StopIteration
生成器
使用了 yield 的函数称为生成器。 yield 是一个关键字,用于定义生成器函数,在迭代的过程中逐步产生值,而不是一次性返回所有的结果。
lambda
使用 lambda 创建匿名函数
通常是用于编写简单的、单行的函数,通常在需要函数作为参数传递的情况下使用,例如:
- map()
- filter()
- reduce()
# 计算乘积,输出120
numbers = [1,2,3,4,5]
product = reduce(lambda x,y :x * y ,numbers )
print(product)
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # 输出:[2, 4, 6, 8]
装饰器 Decorators
装饰器是 Python 的一种高级功能,允许动态地修改函数或者类的行为。
装饰器是一种函数,接受一个函数作为参数,并返回一个新的函数或者修改原来的函数。 装饰器的语法使用 @decorator_name 来应用在函数或者方法上。
还提供一些内置的装饰器,用于定义静态方法和类方法以及属性。如:
- @staticmethod
- @classmethod
- @property
@decorator_function
def function_name():
pass
# 等价于
def function_name():
pass
function_name = decorator_function(function_name)
def decorator_function(func):
def wrapper_function(*args, **kwargs):
# 装饰器逻辑
result = func(*args, **kwargs)
# 装饰器逻辑
return result
return wrapper_function
# 类装饰器
class decorator_class(object):
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
# 装饰器逻辑
result = self.func(*args, **kwargs)
# 装饰器逻辑
return result
@decorator_class
def function_name():
pass
# 等价于
def function_name():
pass
function_name = decorator_class(function_name) # 实例化装饰器类
模块
模块包含了一些常用的函数和类,可以直接导入使用。
模块的导入方式有两种:
- import 模块名
- from 模块名 import 成员名
name 是模块的名称,当模块被直接运行时,name 的值为 ‘main’,当模块被导入时,name 的值为模块名。
dir() 函数可以查看模块内定义的所有名称。如果没有指定参数,则返回当前模块的所有名称。
import math
print(dir(math))
包时一种管理模块的结构,可以将相关的模块放在一个包中,通过包名来导入模块。
包的导入方式:
- import 包名
- from 包名 import 成员名
包的目录结构:
- 包名
- init.py
- 模块1.py
- 模块2.py
- …
目录中有一个 init.py 文件,它是包的初始化文件,当包被导入时,该文件会被自动执行。
包的作用:
- 避免命名冲突
- 组织代码
- 隐藏实现细节
- 共享代码
从一个包中导入 * ,可以导入包中的所有模块。
存在一个 all 列表,它包含了包中所有模块的名称,如果没有 all 列表,则默认导入包中的所有模块。
from mypackage import *
异常处理
Python 使用 try-except 语句来处理异常。
try:
# 可能发生异常的代码
except ExceptionName:
# 异常处理代码
如果没有指定异常类型,则会捕获所有的异常。
try:
# 可能发生异常的代码
except:
# 异常处理代码
如果有多个异常类型需要处理,可以用元组来指定多个异常类型。
try:
# 可能发生异常的代码
except (Exception1, Exception2):
# 异常处理代码
如果想在异常发生时,执行一些代码,可以用 else 语句。
try:
# 可能发生异常的代码
except:
# 异常处理代码
else:
# 正常处理代码
如果想在异常发生时,执行一些代码,并且不再向上层抛出异常,可以用 finally 语句。
try:
# 可能发生异常的代码
except:
# 异常处理代码
else:
# 正常处理代码
finally:
# 最终处理代码
调试
Python 提供了 pdb 调试器,可以设置断点、单步执行代码、查看变量、查看调用栈等。
import pdb
def my_func(x):
y = x + 1
pdb.set_trace()
z = y + 2
return z
my_func(1)
输入和输出
输入
Python 使用 input() 函数来获取用户输入。
name = input("请输入你的名字:")
print("你好," + name)
输出
Python 使用 print() 函数来输出内容到控制台。
print("Hello, world!")
print() 函数可以接受多个参数,参数之间用逗号隔开。
print("Hello,", "world!")
print() 函数还可以指定输出内容的格式,如:
print("Hello, world!", end="")
print("Hello, world!")
end=”" 参数用于指定 print() 函数的换行方式,默认是换行。
文件输入输出
Python 使用 open() 函数来打开文件,并返回一个文件对象。
f = open("test.txt", "r")
open() 函数的第一个参数是文件名,第二个参数是打开模式,“r” 表示以读方式打开文件。
打开模式:
- “r”:读模式,文件必须存在,否则抛出 FileNotFoundError 异常。
- “w”:写模式,文件不存在时创建,存在时覆盖。
- “a”:追加模式,文件不存在时创建,存在时在末尾追加。
- “r+":读写模式,文件必须存在,否则抛出 FileNotFoundError 异常。
- “w+":读写模式,文件不存在时创建,存在时覆盖。
- “a+":读写模式,文件不存在时创建,存在时在末尾追加。
文件对象有以下方法:
- read():读取文件内容,返回字符串。
- readline():读取文件的一行内容,返回字符串。
- readlines():读取文件的所有内容,返回列表。
- write():写入文件内容,返回写入的字符数。
- close():关闭文件。
# 读模式
f = open("test.txt", "r")
content = f.read()
print(content)
f.close()
# 写模式
f = open("test.txt", "w")
f.write("Hello, world!")
f.close()
# 追加模式
f = open("test.txt", "a")
f.write("Hello, world!")
f.close()
面向对象
类的专有方法:
- init():构造函数,在对象创建时调用。
- str():打印对象时调用,返回字符串。
- del():对象被删除时调用。
- len():返回对象的长度。
一些标准库
- os 模块
- sys 模块
- math 模块
- random 模块
- datetime 模块
- json 模块
- re 模块 正则模块
- time 模块 处理时间函数
- urllib 模块 ,访问网页处理URL功能
other
pip freeze #查看安装的包
pip install 包名 #安装包
pip uninstall 包名 #卸载包
pip list #查看已安装的包
pip freeze > requirements.txt #导出依赖包
pip install -r requirements.txt #安装依赖包
3.2 - 《Python for Data Analysis》第 3 版
看完语法之后,直接看用Python进行数据分析,这里进行简单整理。 官方在线书籍:地址
目标是学会用pyton进行数据分析,提取特征工程,为机器学习提供数据支撑,进而做出AIOps、智能运维等应用。
必备的python库
- pandas:数据处理、分析
- numpy:数值计算
- matplotlib:数据可视化
- seaborn:数据可视化
- scipy:科学计算
- scikit-learn:机器学习
- statsmodels:统计分析
- tensorflow:深度学习
- keras:深度学习
- pytorch:深度学习
NumPy
python中数值计算的基础包之一,提供了多种数值计算函数,包括线性代数、随机数生成、统计函数等。
对于大多数数据分析应用程序,重点关注的领域是:
- 基于数组的快速操作,用于数据整理和清理、子集和过滤、转换以及任何其他类型的计算。
- 常见的数组算法,如 排序,唯一和集合运算
- 高效的描述统计和聚合/汇总数据
- 分组数据操作
NumPy 为一般数值数据处理提供了计算基础,但是更多的是希望使用 pandas 作为大多数统计或者分析的基础,尤其是表格数据。
pandas 还提供了一些更特定于领域的功能,例如时间序列操作,而 NumPy 中没有这些功能。
NumPy 数组创建函数:
- np.array():从列表或元组创建数组
- np.zeros():创建指定大小的数组,元素值均为0
- np.ones():创建指定大小的数组,元素值均为1
- np.empty():创建指定大小的数组,元素值随机
- np.arange():创建指定范围的数组
ndarray 常用属性和方法:
- shape:数组形状,表示每个维度大小的元组
- dtype:数组元素类型
- ndim:数组维度
- size:数组元素个数
使用 NumPy 数组进行算术运算: 大小相等的数组之间的任何算术运算都会逐个元素的对应算术运算操作。如:
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = a + b
print(c)
# 输出:[5 7 9]
b > a
# 输出:[true True True] ,相同大小的数组之间的比较会产生布尔数组
索引和切片
一维数组的话就和数组类似,下标是索引,切片是切取数组的一部分,肯前否后。如 arr[5:6]
arr[1:4] = 12 ,将 12赋值给数组 arr 的索引 1 到 3 的元素。
注意:修改了切片中的值之后,原数组也会发生变化。可以使用 arr[5:8].copy() 复制一份副本,然后再赋值。
在二维数组中,索引和切片的用法类似,只是多了一个维度。如 arr[2,3] 或者 arr[1:3,2:4]。
布尔索引:
布尔索引是指利用数组中布尔值来选择元素的一种方法。
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
bool_arr = arr > 2
new_arr = arr[bool_arr]
print(new_arr)
#输出:[3 4 5]
python 中的关键字 and 和 or 不适用于布尔数组,需要使用 & 和 | 来进行布尔运算。
伪随机数生成
numpy.random 模块提供了多种生成伪随机数的方法。如,可以使用一下方法从标准正态分布中获取 4 * 4 样本数:
import numpy as np
samples = np.random.standard_normal(size = (4, 4))
print(samples)
随机数生成器方法:
- permutation():随机排列数组元素
- shuffle():随机打乱数组元素
- uniform():生成均匀分布的随机数
- integers() 从给定的低到高范围内抽取随机整数
- standard_normal():从均值为0、标准差为1的正态分布中抽取随机数
- normal():从正态(高斯)分布中抽取样本
- beta():从beta分布中抽取样本
- binomial():从二项分布中抽取样本
- chisquare():从卡方分布中抽取样本
- uniform() 从均匀[0,1]分布中抽取样本
通用函数
一元通用函数:
- abs,fabs 逐个元素计算整数、浮点数或者复数的绝对值
- sqrt 计算数组元素的平方根
- exp 计算数组元素的指数
- log 计算数组元素的自然对数
- square 计算数组元素的平方
- ceil 向上取整
- floor 向下取整
- rint 四舍五入
- sign 计算数组元素的符号
- modf 整数部分和小数部分分离
二进制通用函数:
- add 逐个元素相加
- subtract 逐个元素相减
- multiply 逐个元素相乘
- divide 逐个元素相除
- maximum 逐个元素比较大小,取最大值
- minimum 逐个元素比较大小,取最小值
- fmax 逐个元素比较大小,取最大值
数学统计方法
聚合函数,如 sum mean median min max std var
对于多维数组,可以带上参数 axis = ? 来计算给定轴上的数据,从而生成一个少一个维度的数组。
如 arr.mean(axis=1) 表示各行的平均值, arr.sum(axis=0) 表示各列的和。
sum():计算数组元素的和
mean():计算数组元素的平均值
median():计算数组元素的中位数
min():计算数组元素的最小值
max():计算数组元素的最大值
std():计算数组元素的标准差
var():计算数组元素的方差
Pandas
pandas 是 Python 中最常用的数据处理库,它提供了高级的数据结构和数据分析工具。
pandas 主要有以下特点:
- 表格型数据结构:DataFrame,类似于 Excel 表格
- 丰富的数据处理功能:数据清理、转换、合并、重塑等
- 高效的数学和统计运算:数据聚合、描述统计、回归分析等
- 时间序列分析:时间序列数据分析、时间序列预测等
DataFrame
DataFrame 是 pandas 中最常用的表格型数据结构,它类似于 Excel 表格,具有行和列索引,可以存储不同类型的数据。
DataFrame 可以通过如下方式创建:
import pandas as pd
# 从字典创建 DataFrame
data = {'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 35]}
df = pd.DataFrame(data)
print(df)
# 输出:
name age
0 Alice 25
1 Bob 30
2 Charlie 35
# 从列表创建 DataFrame
data = [['Alice', 25], ['Bob', 30], ['Charlie', 35]]
df = pd.DataFrame(data, columns=['name', 'age'])
print(df)
# 输出:
name age
0 Alice 25
1 Bob 30
2 Charlie 35
# 从 NumPy 数组创建 DataFrame
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
df = pd.DataFrame(data, columns=['a', 'b', 'c'])
print(df)
# 输出:
a b c
0 1 2 3
1 4 5 6
2 7 8 9
DataFrame 常用属性和方法:
- shape:返回 DataFrame 的行数和列数
- index:返回行索引
- columns:返回列索引
- values:返回 DataFrame 的值
- info():打印 DataFrame 的信息
- describe():计算 DataFrame 的汇总统计信息
- head():返回 DataFrame 的前几行
- tail():返回 DataFrame 的后几行
- loc[]:通过标签选择数据
- iloc[]:通过位置选择数据
- at[]:通过标签获取单个值
- iat[]:通过位置获取单个值
- sort_values():按指定列排序
- sort_index():按索引排序
- apply():对 DataFrame 进行函数操作
Series
Series 是 pandas 中另一种重要的数据结构,它类似于一维数组,但可以包含多个数据类型。
Series 可以通过如下方式创建:
import pandas as pd
# 从列表创建 Series
data = [1, 2, 3, 4, 5]
s = pd.Series(data)
print(s)
# 输出:
0 1
1 2
2 3
3 4
4 5
dtype: int64
# 从字典创建 Series
data = {'Alice': 25, 'Bob': 30, 'Charlie': 35}
s = pd.Series(data)
print(s)
# 输出:
Alice 25
Bob 30
Charlie 35
dtype: int64
Series 常用属性和方法:
- shape:返回 Series 的长度
- index:返回索引
- values:返回 Series 的值
- dtype:返回 Series 的数据类型
- nunique():计算 Series 中唯一值的个数
- unique():返回 Series 中唯一值的数组
- sort_values():按值排序
- sort_index():按索引排序
- apply():对 Series 进行函数操作
- isin():判断值是否在 Series 中
- dropna():删除缺失值
- fillna():填充缺失值
- replace():替换指定值
- map():对值进行映射
- astype():转换数据类型
重建索引 reindex
reindex() 方法可以重新设置 DataFrame 的索引。
对于时间序列等有序数据,可以在重新索引时对数据进行填充、对齐等操作。
- ffill():用前一个值填充缺失值
- bfill():用后一个值填充缺失值
reindex 函数参数:
- labels:新的索引标签
- method:填充方式,ffill 前一个值,bfill 后一个值
- axis:0 行索引,1 列索引
- columns:指定列名,默认是所有列
- limit: 最大填充次数,默认是无穷大
- level:多级索引的层级,否则选择子集
- copy : 是否复制数据,默认是 True
删除index
drop() 方法可以删除指定列或行。
pd.Series(np.arange(5.),index=[‘a’,‘b’,‘c’,’d’,’e’]).drop(‘c’)
输出:
a 0.0
b 1.0
d 3.0
e 4.0
dtype: float64
时间序列处理
pandas 提供了一些时间序列处理的函数,如日期的解析、转换等。
- to_datetime():将字符串转换为日期格式
- date_range():生成日期序列
- resample():重采样数据
import pandas as pd
# 解析日期字符串
dates = ['2019-01-01', '2019-01-02', '2019-01-03']
df = pd.DataFrame({'value': [1, 2, 3]}, index=pd.to_datetime(dates))
print(df)
# 重采样数据
df = pd.DataFrame({'value': [1, 2, 3, 4, 5, 6, 7, 8]}, index=pd.date_range('2019-01-01', '2019-01-08'))
df = df.resample('D').sum()
print(df)
读取和写入文件
pandas 具有许多用于将表格数据读取为 DataFrame 对象的函数,如 pandas.read_svc 就是这本书中最常用的函数之一
将文本数据转换为 DataFrame :
- read_csv():读取 CSV 文件
- read_excel():读取 Excel 文件
- read_json():读取 JSON 文件
- read_html():读取 HTML 文件
- read_sql():读取 SQL 数据库
- read_fwf():读取固定宽度文件
- read_clipboard():读取剪贴板数据
pd.read_csv(‘data.csv’,keep_default_na=False),na_values=[‘NA’]
read_csv() 函数参数:
- path :文件路径
- header:行索引,默认是第一行
- names:列名
- index_col:列索引,默认是第一列
- skiprows:跳过的行数
- na_values:缺失值列表
- data_parser:自定义数据解析器
- skip_footer:跳过的行数
- keep_default_na:是否保留缺失值
- thousands:千位分隔符
分段读取文本文件,先将 pandas 设置的更紧凑一些:
pd.options.display.max_rows = 10
省略号…表示DataFrame中间的行已被省略。 如果想读取少量的行,避免读取整个文件,可以指定 nrows 参数。
pd.read_csv(‘data.csv’,nrows=10)
要分块读取文件,指定 chunksize 参数:
for chunk in pd.read_csv(‘data.csv’,chunksize=100):
写入文本:
- to_csv():写入 CSV 文件
- to_excel():写入 Excel 文件
- to_json():写入 JSON 文件
可以指定分隔符,为空的时候标记值,以及禁用行和列的标签写入。或者自定义部分列(columns=[‘a’,‘b’])的写入格式。
data.to_csv(‘data.csv’,sep=’|’, na_rep=‘Null’,index=False, header=False)
二进制数据格式:
- pickle 模块可以用于保存和加载 Python 对象到磁盘。使用 to_pickle() 和 read_pickle() 方法可以将 DataFrame 保存为二进制文件。
Excel 文件读取:
excel = pd.ExcelFile(‘file.xlsx’) # 打开 Excel 文件 df = pd.read_excel(‘file.xlsx’, sheet_name=‘Sheet1’) # 读取指定工作表
显示工作表:
excel.sheet_names # 显示工作表名称
读取多个工作表:
dfs = {sheet_name: pd.read_excel(‘file.xlsx’, sheet_name=sheet_name) for sheet_name in excel.sheet_names} # 读取所有工作表
将数据读入 DataFrame中:
excel.parse(shell_name=“Sheet1”)
- index_col:指定索引列,默认是第一列。
要想将 pandas 数据写入 Excel ,需要先创建一个 ExcelWriter 对象,然后调用 to_excel() 方法。
import pandas as pd
# 创建 DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 写入 Excel 文件
writer = pd.ExcelWriter('file.xlsx') # 创建 ExcelWriter 对象
df.to_excel(writer, sheet_name='Sheet1') # 写入数据
writer.save() # 保存文件
writer.close() # 关闭文件
HDF5 文件格式:
先安装 PyTables 库:
pip install tables
HDFStore 类可以将 pandas DataFrame 保存为 HDF5 文件。
import pandas as pd
import tables
# 创建 DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 写入 HDF5 文件
with pd.HDFStore('file.h5') as store:
store['df'] = df # 保存 DataFrame
# 读取 HDF5 文件
with pd.HDFStore('file.h5') as store:
df = store['df'] # 读取 DataFrame
HDFStore 类常用方法:
- put():保存 DataFrame
- get():读取 DataFrame
- select():选择 DataFrame 的子集
- remove():删除 DataFrame
- keys():返回 DataFrame 的键列表
数据清理和准备
通常在进行数据分析和建模的过程中,大量的时间都花在数据准备上,包括数据清理、数据转换、数据合并、数据重塑等。
pandas 提供了丰富的数据清理和准备功能,包括缺失值处理、数据转换、字符串处理、数据合并、数据重塑等。
1.处理缺失数据
对于具有 float64 的 dtype的数据, pandas 使用浮点值 NaN(Not a Number)来表示缺失值。
data = pd.Series([1.2,-3.3,np.nan,0])
- 可以使用 isna() 方法来检测缺失值,值为空的返回 True,否则返回 False。
- 可以使用 dropna() 方法来删除缺失值。或者 data[data.notna()] 相同的效果,参数可以传递 how=‘any’ 或 how=‘all’ 来删除所有或任意缺失值。
- 可以使用 fillna() 方法来填充缺失值。
3.3 - 机器学习的数学基础
学习机器学习要先掌握数学基础。
回顾数学基础知识,包括线性代数、概率论、统计学、数值计算等。
- 线性代数
- 矩阵和向量运算
- 特征值和特征向量
- 奇异值分解(SVD)
- 主成分分析(PCA)
- 统计学
- 概率论基础(概率分布、条件概率等)
- 常见概率分布(高斯分布、多项分布等)
- 抽样方法
- 估计与假设检验
- 贝叶斯统计
- 微积分
- 导数和偏导数
- 梯度
- 矩阵微积分
- 最优化方法(梯度下降、牛顿法等)
- 算法和数据结构
- 基本数据结构(数组、链表、树、哈希表等)
- 递归与动态规划
- 算法复杂度分析
- 信息论
- 熵及其意义
- 数据压缩编码
- 交叉熵与相对熵
- 其他数据处理
- 缺失值处理
- 数据规范化
- 维数灾难
- 特征工程
3.3.1 - 数学常识
P(y=1∣x)
P(y=1∣x)表示在给定x条件下,事件y=1发生的概率。这种写法是条件概率的一种表现形式,用于描述一个事件在另一个已知事件发生的情况下发生的概率。
条件概率的定义: 条件概率 P(A | B)定义为事件B发生的情况下,事件A发生的概率,记作P(A|B)。
条件概率的计算公式:P(A|B) = P(A∩B) / P(B)
其中 P(A∩B) 表示事件A和B同时发生的概率,P(B) 表示事件B发生的概率。
举例:
通常在逻辑回归模型中使用,在给定特征x的情况下,预测样本y=1的概率。
例如:在给定性别为男性的情况下,预测样本是否会购买产品的概率。
3.3.2 - 1. 线性代数
线性代数
线性代数
线性代数
线性代数学习大纲:
矩阵和向量
- 矩阵和向量的定义
- 矩阵和向量的基本运算(加法、数乘、转置等)
- 矩阵乘法及其性质
- 逆矩阵
- 矩阵分解(LU分解等)
向量空间
- 向量空间概念
- 线性无关
- 基和维数
- 子空间
- 秩
- null空间和列空间
特征值和特征向量
- 特征值和特征向量的定义
- 对角化
- 相似矩阵
- 特征值分解
- 矩阵的幂
- 线性变换
奇异值分解(SVD)
- 奇异值分解的定义
- 计算SVD
- SVD在降噪、压缩等应用
- 伪逆
主成分分析(PCA)
PCA的动机
协方差矩阵
计算PCA
降维
PCA在数据处理中的应用
向量: 可以进行加减乘除操作的任意对象,如计算机中的数组
标量:一个单独的数字,对向量进行缩放
张量:向量和矩阵的另一种说法,向量是一阶张量,矩阵是二阶张量,图像是三阶张量(高度、宽度、颜色通道)
线性组合:将向量按照一定的比例相加得到的新向量
矩阵:一个二维数组,本质是对运动的描述
单位矩阵: 任意向量与单位向量的乘积,等于什么都没做。
秩: 经过线性变换后空间的维数,即该矩阵的线性无关的行列的最大数目。
范数:向量的长度或大小,常用的是欧式距离。
零向量:长度为零的向量。
零矩阵:所有元素都为零的矩阵。
行列式:矩阵的行列式的值,用来衡量矩阵的正负、奇偶性、逆矩阵的存在性。
逆矩阵:矩阵的逆矩阵,即与矩阵相乘的结果为单位矩阵。
特征分解:将矩阵分解为其特征向量和特征值。
在数学中,任意两个数在进行一种运算后,结果仍在这个集合中,那么这个集合对于这种运算是封闭的。 当初始拥有一定数量的向量后,进行假发和数乘运算,可能产生的整个向量集合是什么?这就引出了向量空间的概念。
线性组合
线性组合是指将一组向量按照一定的比例相加得到的新向量。
设有向量$a_1,a_2,…,a_n$,权重$w_1,w_2,…,w_n$,则$w_1a_1+w_2a_2+…+w_na_n$就是一个线性组合。
线性相关就是向量组中至少有一个向量都可以用向量组中的其他向量的线性组合来表示。换句话说,这个向量落在了其他向量所张成的空间中。
线性无关就是向量组中没有任一向量可以用其他向量的线性组合表示。向量组中的每一个向量都为向量组所张成的空间贡献了一个维度,每一个向量都缺一不可, 少了任何一个向量,都会改变向量组所张成的空间。
- 一组向量要么是线性相关,要么是线性无关,没有第三种情况。
- 如果一组向量中有至少一个零向量,或者有两个相同的向量,那么肯定线性相关。
基的定义
设$V$是向量空间$V$,$v_1,v_2,…,v_n$是$V$中的向量,$B$是$V$的一组基,如果$B$中的每一个向量都可以由$v_1,v_2,…,v_n$中的向量线性表示,那么$B$就是$V$的一组基。 简单点就是向量空间中的一组向量满足:互相线性无关,张成V,则它们是向量空间V的一组基。该空间的任意向量都能表达为基向量的线性组合。
基含有的向量的数量叫做维数(即该向量空间的维数,记作 dim(V))。同一个向量空间可以有不同的基,但同一个基的维数是相同的。
线性变换
如果一个变换同时具有以下2条性质,那么它就是线性变换:
- 变换前后,所有的直线仍保持直线;
- 变换前后,所原点保持不变
向量刻画对象,矩阵刻画对象的运动,用矩阵与向量的乘机施加运动;矩阵的本质是运动的描述。
矩阵与基本运算
矩阵定义: m * n 个数字排成 m * n 列的二维数组就是矩阵,一般用大写字母表示。若 m = n , 则称为n阶方阵或者n阶矩阵。
矩阵的加法与数乘最简答:
- 矩阵的加法:两个矩阵相加,对应元素相加。
- 矩阵的数乘:矩阵与标量相乘,对应元素相乘。
矩阵的乘法:
公式: A 的行 * B 的列相加 。 C的大小为 A行 * B列。
eg:
A = [[1,2],[3,4]] B = [[2,0],[1,2]]
C = A * B
c11 = 1 * 2 + 2 * 1 = 4 c12 = 1 * 0 + 2 * 2 = 4 c21 = 3 * 2 + 4 * 1 = 10 c22 = 3 * 0 + 4 * 2 = 8
C = [[4,4],[10,8]]
def matrix_multiply(A, B):
# 确认A的列数和B的行数相等
if len(A[0]) != len(B):
return None
# 创建结果矩阵
result = [[0 for _ in range(len(B[0]))] for _ in range(len(A))]
# 计算乘积
for i in range(len(A)):
for j in range(len(B[0])):
for k in range(len(B)):
result[i][j] += A[i][k] * B[k][j]
return result
A = [[1, 2],
[3, 4]]
B = [[2, 0],
[1, 2]]
print(matrix_multiply(A, B))
单位矩阵是指对角线上元素都为1,其他元素都为0的矩阵。任意向量与单位矩阵相乘,都不会改变得到自身。
行列式:
对于一个 n * n 的方阵A,行列式det(A)是一个数值,用来表示矩阵的一些特征。
对于一个 2*2 的矩阵 A=[[a,b],[c,d]] ,行列式det(A) = ad - bc
对于一个 3*3 的矩阵 A=[[a,b,c],[d,e,f],[g,h,i]] ,行列式det(A) = aei + bfg + cdh - ceg - bdi - afh
行列式的计算方法:
- 对于 1*1 的矩阵,行列式为 A[0][0]
- 对于 2*2 的矩阵,行列式为 ad - bc
- 对于 3*3 的矩阵,行列式为 aei + bfg + cdh - ceg - bdi - afh
- 对于 n*n 的矩阵,行列式的计算方法为:
- 先将矩阵左上角的元素移到右下角,再将剩下的元素按顺时针方向填入,直到左下角的元素为止。
- 对于填入的元素,如果该元素所在的行列号的和该元素所在的列号的差等于 n-1,则该元素为主元素,否则为次元素。
- 主元素的乘积为该元素所在行列号的和,次元素的乘积为该元素所在行列号的差。
- 最后,所有主元素的乘积相加,再减去所有次元素的乘积。
矩阵的转置:
矩阵的转置是指矩阵的行列互换。
对于一个 n * m 的矩阵 A,它的转置矩阵是 m * n 的矩阵,记作 A^T。
对于一个 2*2 的矩阵 A=[[a,b],[c,d]] ,它的转置矩阵是 [[a,c],[b,d]] 。
对于一个 3*3 的矩阵 A=[[a,b,c],[d,e,f],[g,h,i]] ,它的转置矩阵是 [[a,d,g],[b,e,h],[c,f,i]] 。
逆矩阵
一个方针A,如果存在一个矩阵B,使得 A * B 等于单位矩阵I,则称A是可逆的,B就是A的逆矩阵,记作 A ^ -1。
如果A可逆,则A的逆矩阵存在,且唯一。
矩阵的逆矩阵存在的充分必要条件是矩阵的行列式不为0。
矩阵的逆矩阵的计算方法:
- 首先,计算矩阵的行列式det(A)。
- 然后,如果det(A)不等于0,则计算矩阵的adjugate矩阵adj(A)。
- 最后,计算adj(A)的逆矩阵,即adj(A) * (1/det(A))。
矩阵的秩(rank)是指矩阵的行列式的绝对值,记作 rang(A)。
特征值和特征向量、特征分解与奇异值分解
特征值和特征向量
对于一个方阵A,如果存在一个数λ和一个非零向量v,使得Av = λv,则称λ为A的特征值,v为A的特征向量。 简单说就是,特征向量是将通过矩阵A变换后依然保持方向不变的矢量,特征值是在变换过程中缩放矢量的因子。
求解:
Av-λv = 0 (A-λI)v = 0 ,其中I是单位矩阵,要想这个方程有非零解,必须有: det(A-λI)=0
这个方程称为特征多项式,特征多项式的根即为矩阵A的特征值。
计算特征向量:对于每一个特征值λ,都可以找到一个对应的特征向量v,使得Av = λv。
- 对于2*2的矩阵,特征值只有一个,特征向量就是矩阵的逆矩阵。
- 对于3*3的矩阵,特征值只有3个,特征向量就是矩阵的主对角线上的元素。
- 对于n*n的矩阵,特征值有n个,特征向量就是矩阵的n个主元对应的单位向量。
应用:
- 图像压缩:将图像的像素值压缩到一个小的范围内,使得图像的质量不变,同时减少存储空间。
- 数据降维:特征值和特征向量用于找到数据的主成分,从而实现降维。
- 矩阵运算:特征值和特征向量用于进行矩阵运算,如PCA、SVD等。
- 信号处理:信号的频谱可以分解为低频成分和高频成分,通过奇异值分解可以找到信号的主要成分。
- 系统稳定性分析:特征值判断系统是否是稳定的,如果特征值全部为0,则系统是稳定的。
- 模式识别:特征向量用于特征提取和数据表示。
特征分解
特征分解是指将矩阵A分解为其特征向量和特征值。 对于一个 n * n 的矩阵A,如果存在n个线性无关的特征向量,可以将A分解为: A = v Λ v^-1,其中v是特征向量组,Λ是特征值组。 其中,𝑉 是由特征向量作为列向量构成的矩阵,Λ 是一个对角矩阵,对角线上是对应的特征值。
奇异值分解(SVD)
奇异值分解(SVD)是指将矩阵A分解为三个矩阵U、Σ、V,其中U、V是正交矩阵,Σ是对角矩阵。
应用:
- 数据压缩:svd 用于图像压缩,保留主要特征,减少存储空间。
- 推荐系统: SVD 用于推荐系统,找到用户的兴趣偏好,推荐相关物品。
- 图像处理:SVD 用于图像处理,提取图像的主要特征,并进行降维。
- 矩阵运算:SVD 用于矩阵运算,如PCA、SVD等。
- 信号处理:SVD 用于信号处理,提取信号的主要成分。
特征值和特征向量、特征分解与奇异值分解在数据分析、机器学习和各种科学与工程领域中都有重要的应用。通过理解这些概念和它们的计算方法,我们可以更好地分析和处理复杂的数据。
3.3.3 - 2. 概率论基础
概率论基础
概率论基础
概率论基础
概率论与统计学大纲
- 基本概念
- 概率与条件概率
- 随机变量与分布(离散和连续)
- 期望、方差和标准差
- 主要分布
- 二项分布与泊松分布
- 正态分布与均匀分布
- 指数分布与Gamma分布
- 描述性统计
- 均值、中位数和众数
- 分位数与箱线图
- 方差与标准差
- 统计推断
- 点估计与区间估计
- 假设检验与p值
- 置信区间
- 贝叶斯统计
- 贝叶斯定理
- 先验和后验分布
- 贝叶斯统计与推断
基本概念与分布情况
一个概率空间由三元组定义:
- 状态空间/样本空间 : 一个试验所有可能出现的结果
- 事件空间 : 试验的每一个单一结果为一个事件,它是状态空间的子集,而事件空间就是所有事件构成的集合。
- 概率P(A) :描述发生的可能性,也称概率函数。
举个例子来理解上述三个概念。假如我们投掷一个6面骰子,那么样本空间 Ω = {1,2,3,4,5,6}。如果我们关注的事件是骰子点数是奇数还是偶数,那么事件空间就是 F = {∅,{1,3,5},{2,4,6}}
随机变量:
- 定义:设 X 为一个试验,其结果为一个实数值,则 X 称为随机变量。
- 随机变量的分布:随机变量 X 的分布是指随机变量 X 取各个值的概率。
根据状态空间不同,随机变量可以分为离散和连续的。
- 能取有限的值,则该随机变量是离散的,离散随机变量的概率分布通过概率质量函数(PMF)表示,记作P(X=x)
- 能取无限多个值,则该随机变量是连续的,连续随机变量的概率分布通过概率密度函数(PDF)表示,记作f(x)
分布:
概率分布:随机变量取一个特定值的概率, P(X)
边缘分布:一个随机变量对于其自身的概率分布。换句话说,就是在联合分布的情况下,边缘分布就是把另一个变量的所有可能取值相加。
联合分布:由多余一个变量决定的概率分布,即多件事件同时发生的情况, P(X,Y)
条件分布:已知某些事件已经发生的前提下,另一事件发生的概率的分布。P(X|Y)
二项分布:在离散时间上,某事件发生的次数的分布。有两个参数,n,表示试验次数,p表示事件发生的概率。P(X=k) = C(n,k)p^k(1-p)^(n-k) ,其中C(n,k)是组合数,读作n选k,公式 n! / (k!(n-k)!) ,如 C(10,3) = 10!/(3! * 7!)
泊松分布:在连续时间上,某事件发生的次数的分布。只有一个参数,λ,表示事件发生的次数。P(X=k) = e^(-λ)λ^k/k! ,e是自然对数的底,约等于2.71828
正态分布/高斯分布:常见的连续概率分布,在连续时间上,一个随机变量的分布。有两个参数,μ表示分布的均值,σ^2表示方差。P(X=x) = (2πσ^2)^{-1/2}exp(-(x-μ)^2/2σ^2)
多项分布:描述多个类别事件的离散概率分布。有两个参数,n,表示试验次数,p1,p2,…,pk表示各个类别事件发生的概率。次数n 和 每个类别的概率向量 p。公式 P(X1=x1,X2=x2,…,Xk=xk) = (n! / x1!x2!…xk!) * p1^x1 * p2^x2 * … * pk^xk
总结:
- 高斯分布 主要用于描述连续数据的概率分布,定义了均值和标准差。
- 多项分布 则用于描述多个类别的离散数据,在多个类别中统计每个类别出现的次数。
统计推断
从样本数据中获取信息并对总体进行预测和推断,主要设计两大部分:点估计和区间估计。
点估计:用一个单一的数值从样本数据中去估计总体参数。
- 均值估计:用样本均值去估计总体均值
- 方差估计:用样本方差去估计总体方差
如有一个样本数据集{x1,x2,…,xn},样本均值的点估计计算方法是:
x̄ = 1/n ∑(n,i=1) xi
区间估计:用一组数值从样本数据中去估计总体参数的置信区间。
置信区间:表示在一定的置信水平下,总体参数位于某个范围内。
置信水平:置信水平是指总体参数的真实值与估计值的差距所能容忍的最大值。
贝叶斯统计
贝叶斯统计是一种概率论的分支,它利用贝叶斯定理来更新概率估计,在获取新数据时动态调整对未知参数或事件的概率分布。与传统频率派统计不同,贝叶斯统计将概率解释为对某一事件的信心程度,而不仅仅是长期频率。
核心概念:
- 先验概率:在考虑新数据之前,对位未知参数的初始估计。
- 似然函数:根据现有数据计算出,表示数据在特定参数值下出现的概率。
- 后验概率:更新后的概率,结合了先验概率和新数据,反映了在新数据下,参数的估计值。
贝叶斯定理:
- 贝叶斯定理是关于概率的基本定理,它告诉我们如何利用已知的信息来更新不完整的概率分布。
- 贝叶斯定理的基本思想是,已知某件事情发生的概率,可以根据已知的信息来计算另一件事情发生的概率。
- 贝叶斯定理的公式为:P(A|B) = (P(B|A)P(A))/P(B)
例子说明:
Q: 假设我们做市场调查,想知道城市中有多少百分比的人喜欢某种饮料。
- 先验概率:我们不知道城市中有多少百分比的人喜欢某种饮料,根据其他城市的经验估计有20%的人会喜欢。
- 收集数据:我们随机抽取了100个人,其中25人喜欢
- 计算似然函数:对于每个可能的喜欢百分比(从0%到100%),计算这些数据出现的概率。这个概率跟二项分布有关,因此可以用二项公式计算每个可能喜欢百分比下观测到25/100这个结果的概率。
- 应用贝叶斯定理:结合先验概率和似然函数来计算后验概率。计算后,会得到一个更新的概率分布,表示在观测到25个喜欢的人之后,对喜欢百分比的新的信心。
应用:
- 机器学习: 如贝叶斯网络,贝叶斯优化,贝叶斯分类器等
- 医学:
- 经济金融:
- 自然科学
似然函数的解释:
似然函数是在给定参数值下,数据出现的概率。它描述了在假设某个特定参数值时,观察到给定数据的可能性。虽然它和概率密度函数(PDF)/概率质量函数(PMF)有相似之处,但在似然函数中,把参数视为变量,而数据是固定的。
如抛了10次硬币,观测到7次正面朝上,你想估计 𝜃 是多少。
n=10,k=7,函数是 L(𝜃) = c(10 7)𝜃^7(1-𝜃)^3,其中 c(10 7) 是组合数。
为了找到最有可能的 θ,我们通常会最大化这个似然函数(这叫做最大似然估计,MLE)。在实际操作中,这可以通过对数似然函数来简化计算。
直观理解:
- 固定数据,变参数:似然函数固定了数据(如观测到的7正3反),然后变换参数(如 𝜃=0.1,0.2,…,0.9θ=0.1,0.2,…,0.9 等)来看在不同 θ 下这些数据出现的可能性。
- 找到最优θ:似然函数的最大值对应的参数值 𝜃 就是我们认为最有可能使这些数据出现的参数值。
3.3.4 - 3. 导数和偏导数
导数和偏导数
导数和偏导数
导数和偏导数
- 导数
- 梯度
- 矩阵微积分
- 最优化方法(梯度下降、牛顿法等)
导数是一个函数某一点的变化率,对于单变量函数f(x),导数记作 f’(x) 或 df/dx。
偏导数是一个函数有多个变量时,比如f(x,y),对每个变量进行微分,得到偏导数。
梯度:是多变量函数的导数向量,对应每个变量的偏导数,对于函数f(x,y,z),梯度记作 grad f(x,y,z) = (df/dx, df/dy, df/dz)。 梯度指向函数增长最快的反向,梯度的大小(即向量的长度)表示增长率的快慢。
矩阵微积分:对矩阵求导,得到矩阵的雅可比矩阵,即梯度的矩阵形式。
海森矩阵是一个方阵,包含二阶偏导数,通常用户分析函数的曲率。
最优化方法:梯度下降、牛顿法等。
梯度下降
梯度下降:是一种迭代优化方法,用于找到函数的局部或者全局最小值。
算法步骤:
- 随机选择一个起始点x0。
- 计算函数f(x)在x0处的梯度grad f(x0)。
- 确定步长α,使得x1 = x0 - α*grad f(x0)。
- 重复步骤2和步骤3,直到收敛。
牛顿法
牛顿法利用二阶导数(海森矩阵)加快收敛速度,适用于函数曲率信息明显的情况。
算法步骤:
- 随机选择一个起始点x0。
- 计算函数f(x)在x0处的海森矩阵H(x0)。
- 计算函数f(x)在x0处的梯度grad f(x0)。
- 计算矩阵H(x0)的逆矩阵,即H(x0)^-1。
- 确定步长α,使得x1 = x0 - αH(x0)^-1grad f(x0)。
- 重复步骤2-5,直到收敛。
牛顿法需要计算和存储海森矩阵,计算成本较高。
3.3.5 - 4. 基本数据结构
基本数据结构
基本数据结构
基本数据结构
3.3.6 - 5. 熵及其意义
熵及其意义
熵及其意义
熵及其意义
3.3.7 - 6. 缺失值处理
缺失值处理
缺失值处理
缺失值处理
- 数据规范化
- 维数灾难
- 特征工程
缺失值处理:
- 删除法:
- 删除行
- 删除列
- 补全法:
- 均值补全
- 众数补全
- 中位数补全
- 插值法
- 预测法:
- 机器学习算法预测
- 多重插补法
数据规范化:
规范化的目的是将不同的量纲和范围的数据变换到同一量纲和范围,以便后续的分析和建模。
- 最小-最大归一法
- 标准法
- 将数据转化为均值是0,方差是1的正态分布
- 适用于数据分布大致对撑的数据
- max_abs 归一法
- 将每个特征缩放到 |-1,1|范围,但不会改变数据的稀疏性
维数灾难:指的是随着数据特征维度的增加,数据稀疏性大幅增加,导致计算复杂度显著提高,模型表现下降的问题。
解决方法:
- 特征选择:
- 降维技术
特征工程:从原始数据中提取出有代表性且能更好描述数据特征的过程。
- 特征构造:
- 创建新特征:结合现有特征,创建出新的有意义的特征,如两个特征的比值、累积量、时序特征等。
- 分箱处理:将连续特征离散化,适用于某些分类算法,如决策树。
- 交互特征:引入特征之间的交互项,可以捕捉到特征之间更复杂的关系。
- 特征提取:
- 主题模型(如 LDA):从文本数据中提取主题特征。
- 频谱分析:从信号数据中提取频率特征。
- 特征选择:
- 过滤法:通过统计检验或评分函数,选择显著特征。
- 嵌入法:基于模型的特征选择,例如通过正则化方法(Lasso回归)选出的特征。
- 包裹法:使用一个预测模型,评估特征子集的效果,选择最佳子集。
- 特征编码:
- 独热编码(One-Hot Encoding):将类别特征转化为二元矩阵。
- 标签编码(Label Encoding):将类别特征转化为整数标签。
- 目标编码(Target Encoding):用类别特征对应的目标变量的平均值来编码类别特征。
在机器学习中,缺失值处理、数据规范化、维数灾难解决和特征工程是重要的预处理步骤。 它们分别确保了数据的完整性一致性、处理效率、模型性能和特征的有效性。 这些步骤帮助我们从原始数据中提取最具信息量的特征,从而训练出更准确、更可靠的模型。
3.4 - 安装问题
openpyxl安装失败
excel文件操作库openpyxl在安装过程中经常会出现安装失败的情况,原因是由于网络连接不稳定导致的。
解决办法:
pip –default-timeout=200 install openpyxl
tables安装失败
tables库在安装过程中经常会出现安装失败的情况,原因是由于网络连接不稳定导致的。
解决办法:
pip –default-timeout=200 install tables